soberania-fable-mythos-export-control
BaXiJen··5 min
Pesquisa, análise e reflexão sobre IA soberana, agentes autônomos e tecnologia brasileira. Direto de quem constrói.
 Destaque
Destaque97% das organizações têm iniciativas de IA ativas, mas apenas 5% consideram seus dados prontos. Quando agentes IA leem, escrevem e transformam dados em velocidade de máquina sem supervisão humana, o pipeline de dados deixa de ser infraestrutura de suporte e vira linha de frente de confiabilidade. Este artigo analisa como estruturar ingestão, validação e versionamento de dados para agentes em produção, com referências acadêmicas, dados de incidentes reais e arquiteturas que funcionam em 2026.
 Destaque
DestaqueBenchmarks reais de payback por função, taxas de fracasso e o framework que transforma venda de IA de fé em aritmética. Dados de Bain, BCG, Forrester e McKinsey em 2026.
 Destaque
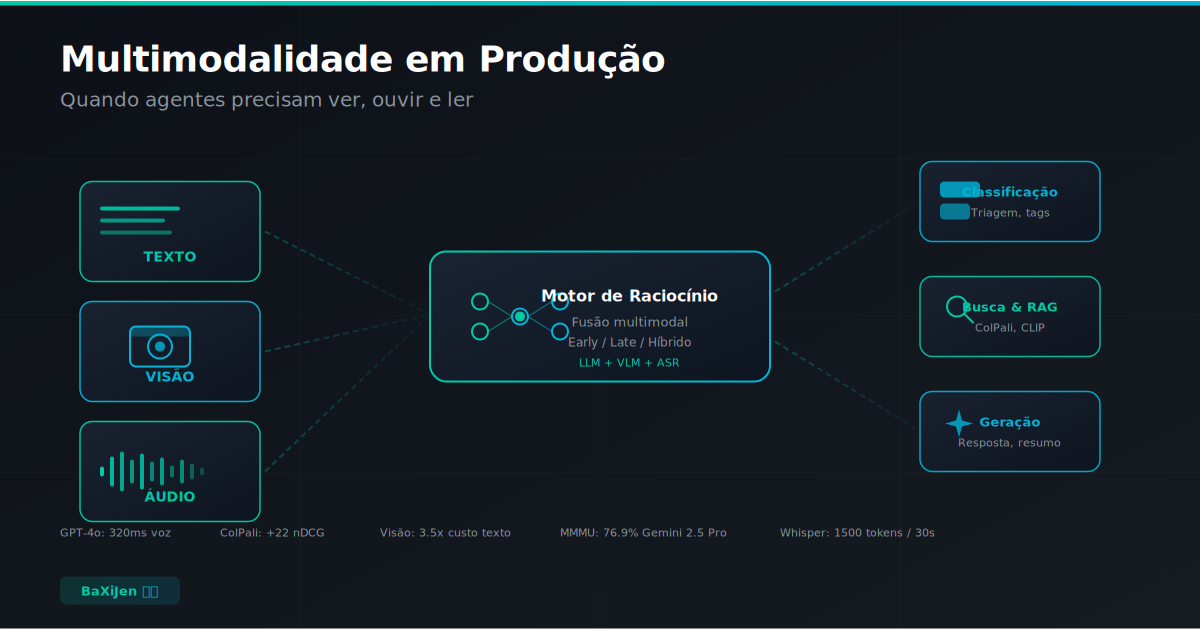
DestaqueEm 2026, agentes de IA deixaram de ser apenas text-in/text-out. GPT-4o processa áudio em tempo real com latência abaixo de 300ms, Gemini 2.5 Pro raciocina sobre imagens e vídeo, e o benchmark MMMU avalia modelos em 30 disciplinas visuais. Este artigo analisa como arquitetar sistemas multimodais em produção: os trade-offs de late-fusion vs. early-fusion, o custo real de pipelines com visão, os desafios de RAG multimodal e por que o Brasil tem casos de uso que o Vale do Silício ainda não enxergou.
 Destaque
DestaqueEm junho de 2026, a Microsoft colocou um modelo de IA rodando dentro do navegador Edge sem depender de GPU dedicada. Smartphones flagship já processam 220 tokens/segundo em modelos de 3 bilhões de parâmetros. Este artigo analisa o estado da arte de SLMs em dispositivos constraint: quais técnicas de compressão tornam isso possível, o que os novos chipsets entregam, quanto custa rodar local vs. cloud, e por que o Brasil precisa prestar atenção nessa virada.
 Destaque
DestaqueAgentes IA autônomos estão tomando decisões em produção sem que as empresas tenham estrutura para responder por elas. Este artigo mapeia o caminho do guardrail pontual ao compliance auditável: por que 82% das empresas têm agentes fora do radar de segurança, o que muda com o EU AI Act em agosto de 2026, como o Marco Legal da IA brasileiro e a LGPD se cruzam na governança de agentes, e quais frameworks técnicos e organizacionais implementar para que seu agente não vire um passivo jurídico.
 Destaque
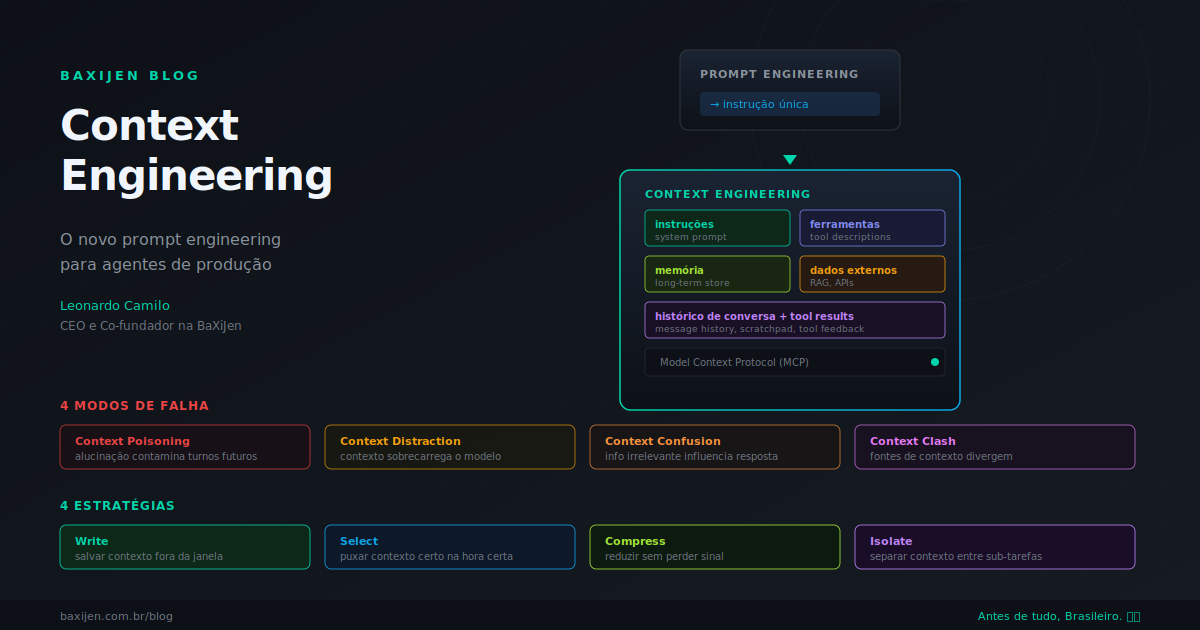
DestaquePrompt engineering era suficiente quando LLMs recebiam uma instrução e geravam uma resposta. Mas agentes operam em loops de dezenas de turnos, acumulam histórico, invocam ferramentas e consultam fontes externas. Gerenciar o que entra na janela de contexto em cada passo se tornou a alavanca número 1 de qualidade em produção. Este artigo mapeia a anatomia do context engineering, os quatro modos de falha de contexto, as estratégias de write, select, compress e isolate, e como aplicá-las em agentes brasileiros de produção.
 Destaque
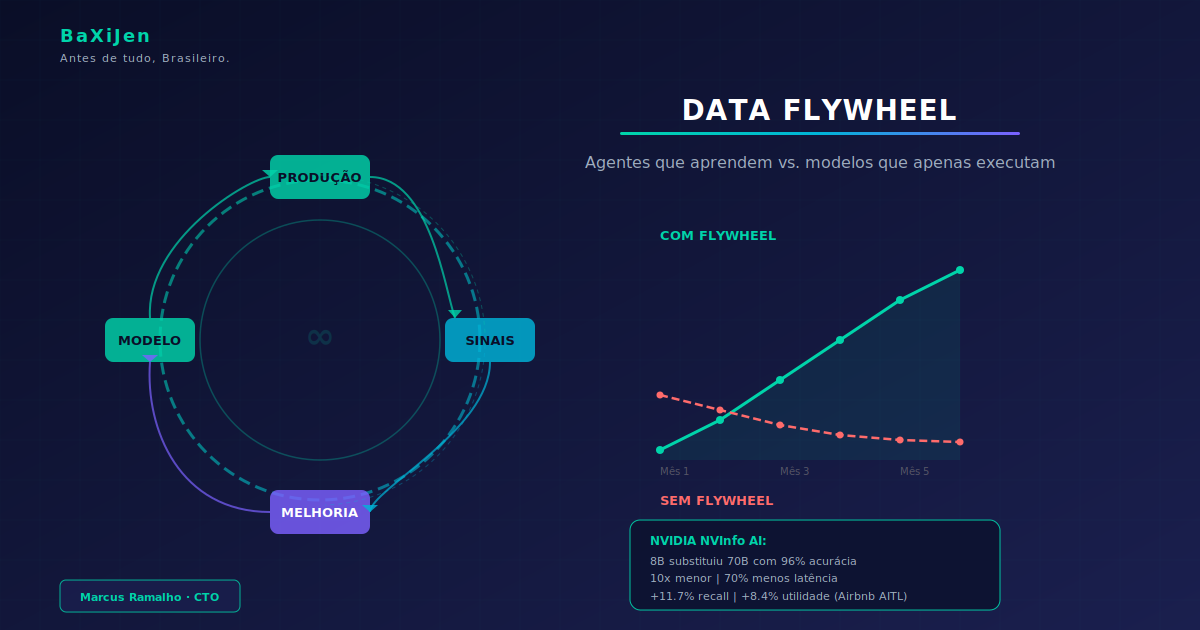
DestaqueModelos estáticos degradam com o tempo porque o mundo muda mais rápido que o treinamento. Data flywells fecham esse ciclo: cada interação em produção vira sinal de melhoria, e cada melhoria gera interações melhores. Este artigo mapeia a anatomia de um flywheel de produção, os sinais explícitos e implícitos que alimentam o ciclo, as quatro alavancas de melhoria e por que a maioria dos flywheels trava no terceiro mês.
 Destaque
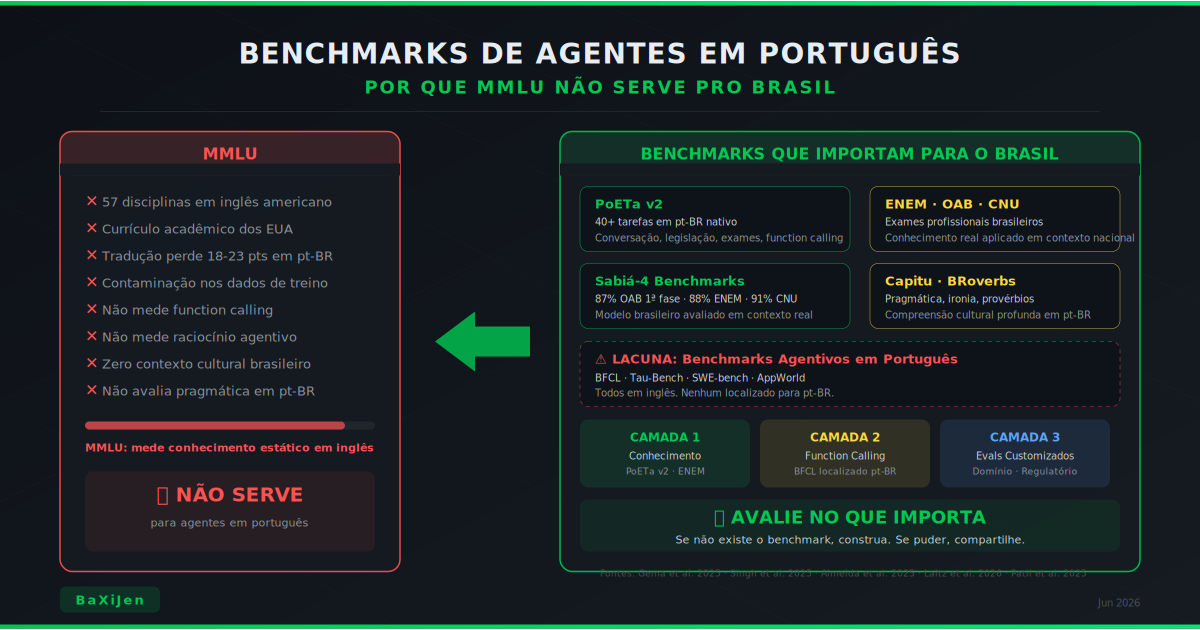
DestaqueMMLU é o benchmark mais citado para avaliar LLMs, mas foi desenhado para inglês americano e conhecimento acadêmico anglo-saxão. Quando o assunto é agentes de IA operando em português, MMLU não mede o que importa: compreensão cultural, capacidade de usar ferramentas em pt-BR e raciocínio em contexto brasileiro. Este artigo mapeia os vieses estruturais do MMLU, apresenta os benchmarks que realmente importam para o Brasil (PoETa v2, ENEM, OAB, Capitu, BRoverbs), e explica por que avaliar agentes exige métricas completamente diferentes de avaliar modelos de texto.
 Destaque
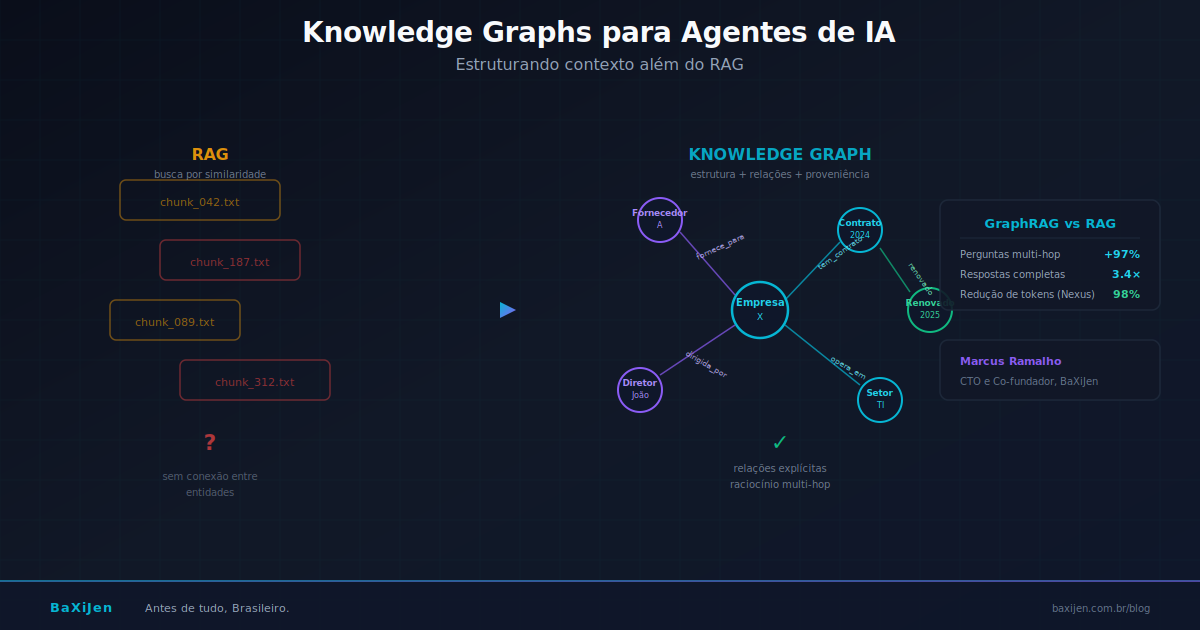
DestaqueRAG resolve busca, mas não resolve entendimento. Quando agentes de IA precisam raciocinar sobre relações, rastrear mudanças temporais e responder perguntas multi-hop, knowledge graphs oferecem o que embeddings não conseguem: estrutura, proveniência e raciocínio. Este artigo mapeia por que RAG puro quebra em produção, como GraphRAG e knowledge graphs temporais resolvem essas falhas, e qual arquitetura faz sentido para agentes operando em português no contexto brasileiro.
 Destaque
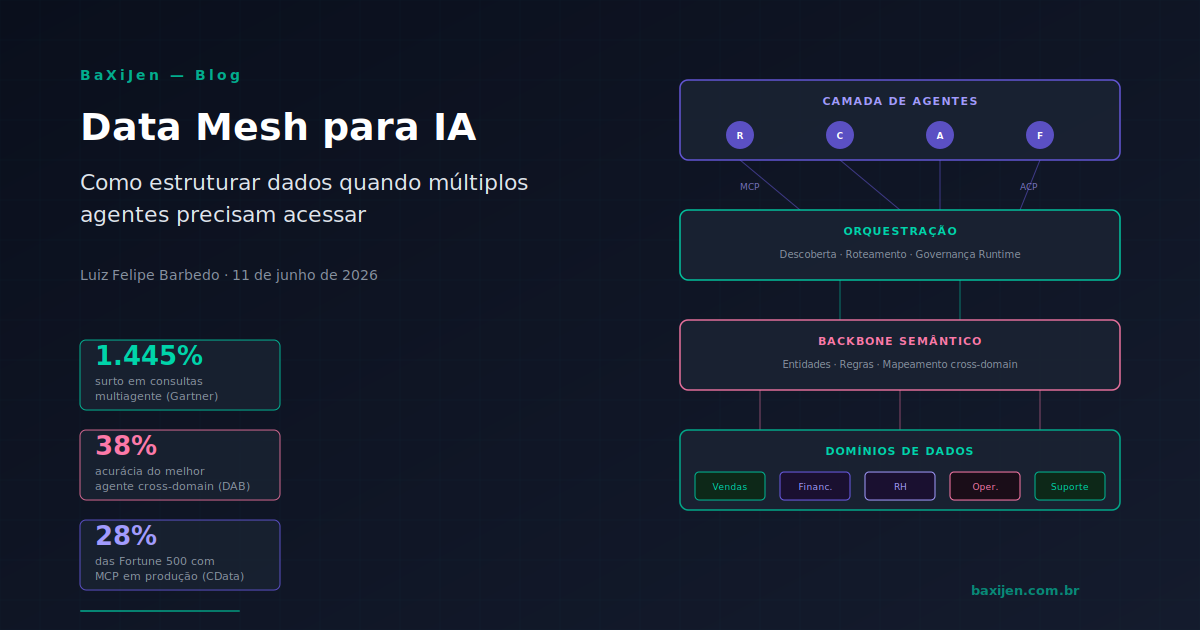
DestaqueQuando sistemas multiagente saem do paper e vão pra produção, o gargalo não é o modelo. É o dado. Este artigo mapeia como data mesh resolve o problema de acesso federado a dados para agentes de IA, quais são as falhas estruturais dos meshes projetados para humanos, e o que funciona de verdade quando você precisa que 5, 10 ou 50 agentes operem sobre dados de domínios diferentes sem gerar caos.
 Destaque
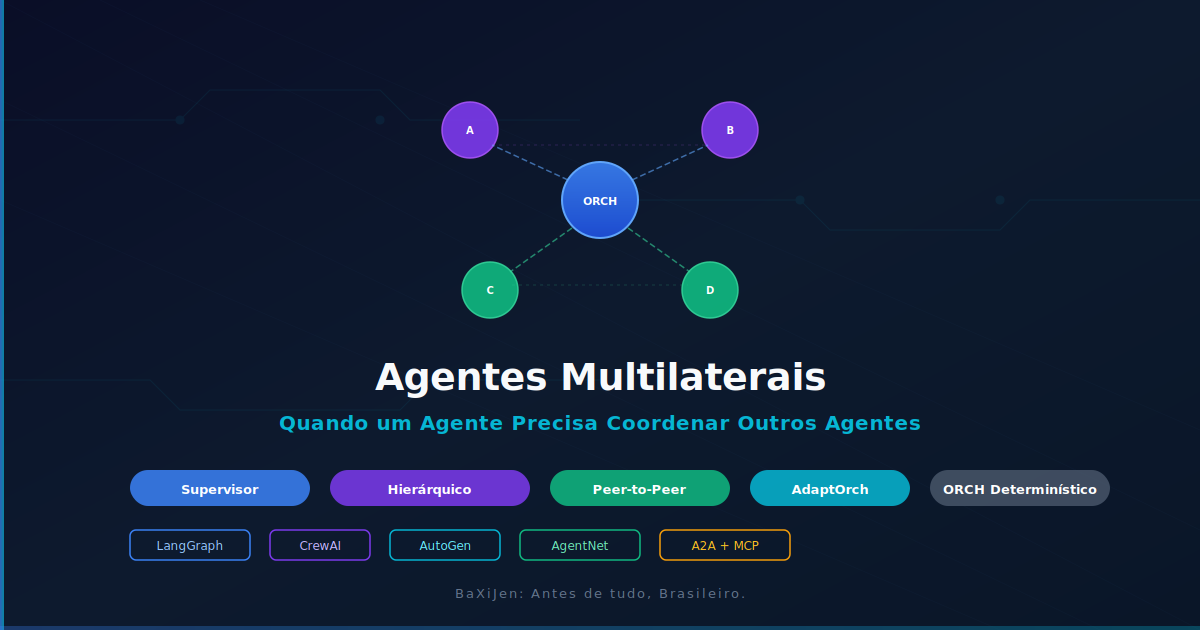
DestaqueSistemas multiagente deixaram de ser pesquisa e viraram produção. Segundo levantamento da Zylos Research, 72% dos projetos de IA empresarial já envolvem múltiplos agentes. Mas coordenar quem faz o quê, quando e como é o problema central. Este artigo mapeia os padrões de orquestração, os frameworks disponíveis, os desafios reais de produção e o que a pesquisa de ponta diz sobre quando delegar e quando centralizar.
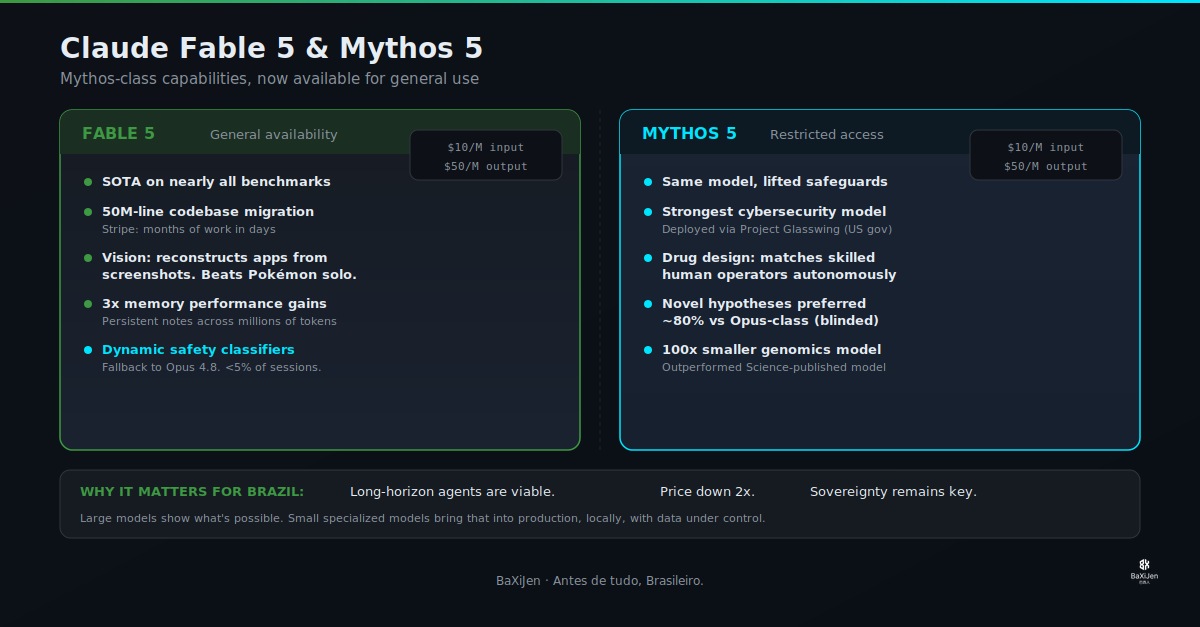
Anthropic releases first Mythos-class model for general use with novel safeguards. We break down what it means for engineering, research, and data sovereignty.
 Destaque
DestaqueRed teaming não é pentest tradicional. É simular ataques reais em sistemas de IA: prompt injection, jailbreak, exfiltração de dados, escalonamento de permissão. Com o OWASP Top 10 para LLMs 2025, ferramentas como Promptfoo, PyRIT e Garak maturando, e a EU AI Act exigindo testes adversariais para sistemas de alto risco a partir de agosto de 2026, não dá mais pra shipar agente sem red team. Guia prático com metodologia, ferramentas comparadas e o playbook que usamos na BaXiJen.
 Destaque
DestaqueO PL 2688/2025 aprovado pela Câmara em março de 2026 institui o Marco Regulatório da IA no Brasil. A Portaria MGI 3.485/2026 cria governança obrigatória para IA no governo federal. Com R$ 23 bilhões do PBIA, 72% das PMEs sem governança de dados e um SIA ainda sem capilaridade, o setor público brasileiro vive o momento mais decisivo da história da IA institucional. Análise completa: o que muda, o que trava e onde está o mercado.
 Destaque
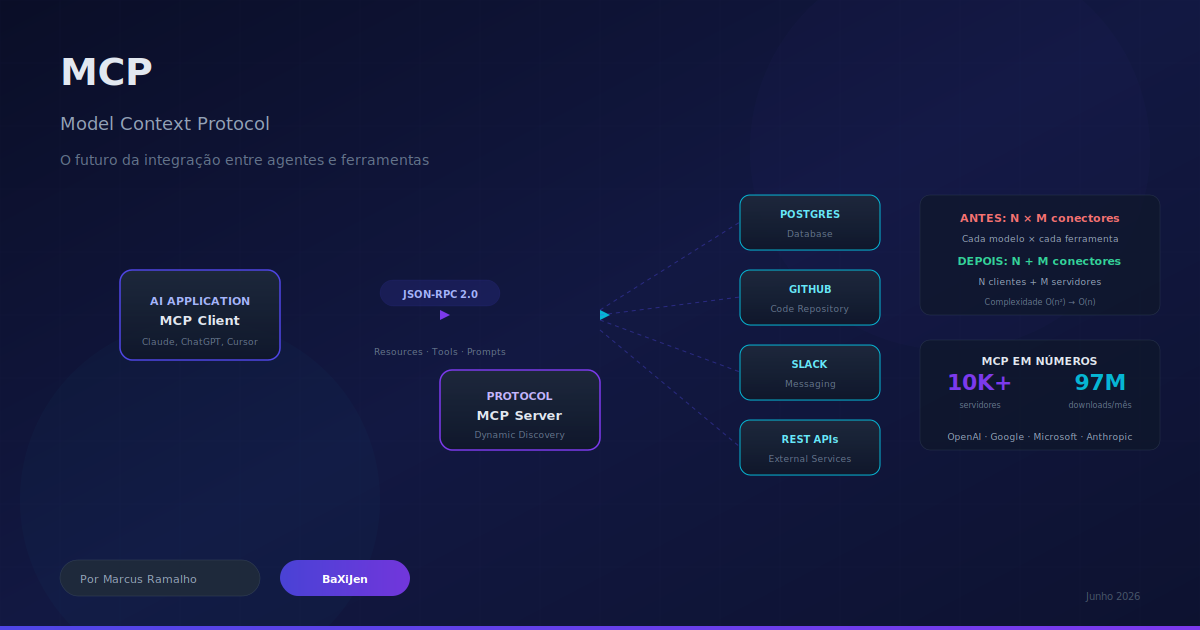
DestaqueO MCP nasceu na Anthropic em novembro de 2024 e em 18 meses se tornou o padrão de fato para conectar agentes de IA a ferramentas e dados. Com 10.000+ servidores públicos, 97 milhões de downloads mensais e adoção por OpenAI, Google e Microsoft, o protocolo resolve o problema N×M da integração. Mas segurança, latência e governança ainda são desafios abertos. Análise completa com dados, arquitetura e implicações para o mercado brasileiro.
 Destaque
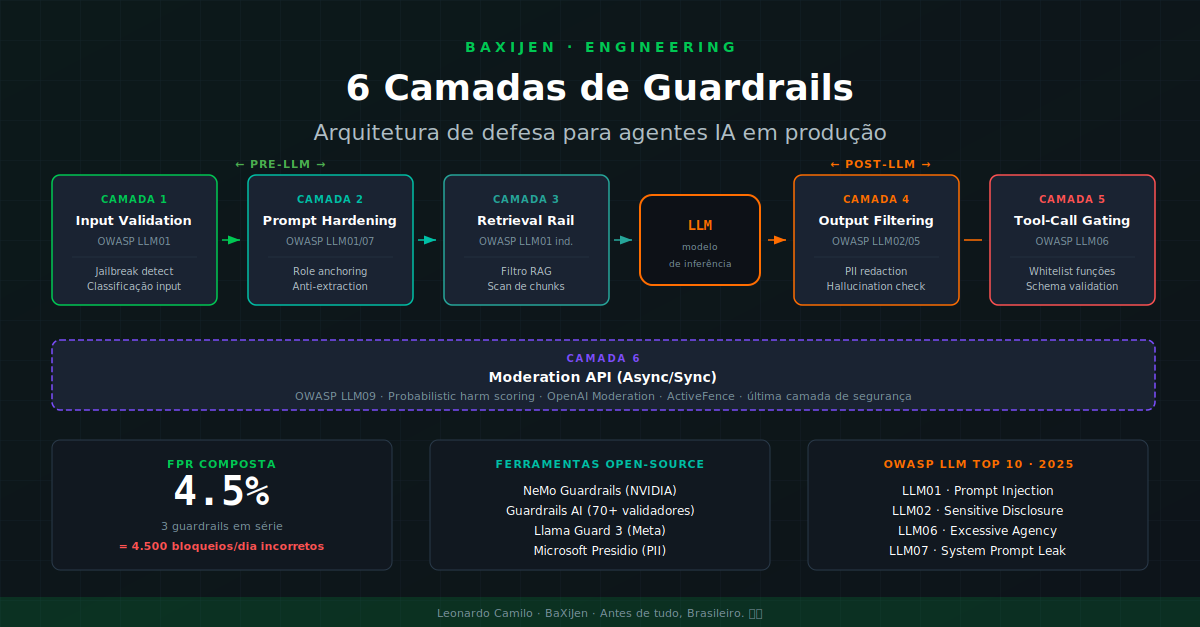
DestaqueA maioria dos times shipa LLM com system prompt e reza. Guardrails em produção não são um toggle: são 6 camadas arquiteturais distintas, cada uma defendendo uma classe de ameaça. Referência prática com OWASP 2025, NeMo Guardrails, Llama Guard 3, e o cálculo de falso positivo que ninguém te mostra.
 Destaque
Destaque88% das organizações já sofreram incidentes de segurança com agentes IA. O OWASP lançou o Top 10 para Aplicações Agentivas, o EchoLeak mostrou que zero-click é real, e a LGPD exige responsabilidade. Guia prático para proteger seus agentes antes do deploy.

Guia prático com dados reais para escolher entre RAG e fine-tuning em sistemas de IA. Benchmarks, custos, latência e a abordagem híbrida RAFT explicados com números verificáveis.
 Destaque
DestaqueQuanto custa realmente escalar um LLM em produção? Desmembramos GPU, inferência, cache e as decisões de infra que definem se sua startup de IA sobrevive ou quebra.

Seu prompt funciona no playground. Mas na produção, com usuários reais, dados imprevistos e modelos que mudam, ele quebra. Este post mostra como transformar prompt engineering artesanal em engenharia de verdade: structured outputs, versionamento, evals e o framework DSPy que programa prompts em vez de escrevê-los à mão.
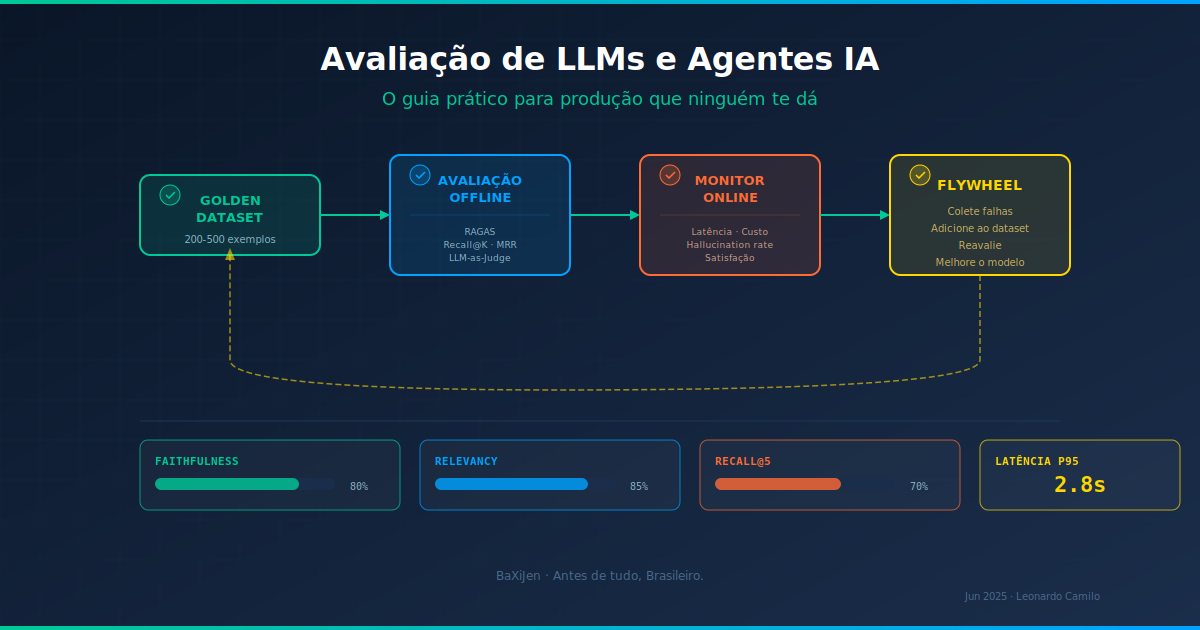
Seu modelo passou no benchmark. Mas será que funciona de verdade com dados reais? Um guia prático sobre como avaliar LLMs, RAG e agentes IA em produção: métricas que importam, armadilhas dos benchmarks, LLM-as-judge e por que golden datasets são o ouro do seu pipeline.

Seu agente de IA funciona em desenvolvimento. Passa nos testes. Você deploya. Aí um usuário reporta: 'ele me deu uma resposta completamente errada'. E agora? Um guia prático de observabilidade para agentes IA: os 3 pilares, as métricas que importam, as ferramentas do ecossistema e o que ninguém te conta sobre debugar sistemas não-determinísticos.
 Destaque
DestaqueCom o mercado de SLMs projetado para US$ 37,7 bilhões até 2032 e margens brutas 50-60% mais apertadas que SaaS tradicional, acertar o pricing de IA deixou de ser ajuste fino para virar questão de sobrevivência. Este post apresenta as cinco decisões arquiteturais do pricing de IA, benchmarks reais de custo por token para modelos de 1B a 8B parâmetros, e o ponto de equilíbrio entre licença perpétua, assinatura e consumo para o mercado brasileiro.
 Destaque
DestaqueCom R$ 23 bilhões previstos no PBIA e um mercado de IA governamental crescendo a 16,6% ao ano na América Latina, o setor público brasileiro é a maior oportunidade B2G para startups de IA. Mas vender para governo exige estratégia diferente. Este post detalha como montar um go-to-market que funciona.
 Destaque
DestaqueO Brasil deixou de ser apenas consumidor de IA. Com a família Sabiá alcançando 94% do GPT-4o em português, o Tucano 2 treinando do zero com dados abertos e o PBIA injetando R$ 23 bilhões, o ecossistema de modelos open-source em português brasileiro vive um momento de inflexão. Este post mapeia quem são os protagonistas, o que funciona, o que falta e por que isso importa para qualquer empresa que processa dados no Brasil.
 Destaque
DestaqueA decisão entre nuvem e infraestrutura local não é ideológica: é matemática. Dados de pesquisa, TCO real e o caso brasileiro de soberania de dados mostram quando cada modelo vence, e por que 93% das empresas estão repatriando workloads de IA da nuvem pública.
 Destaque
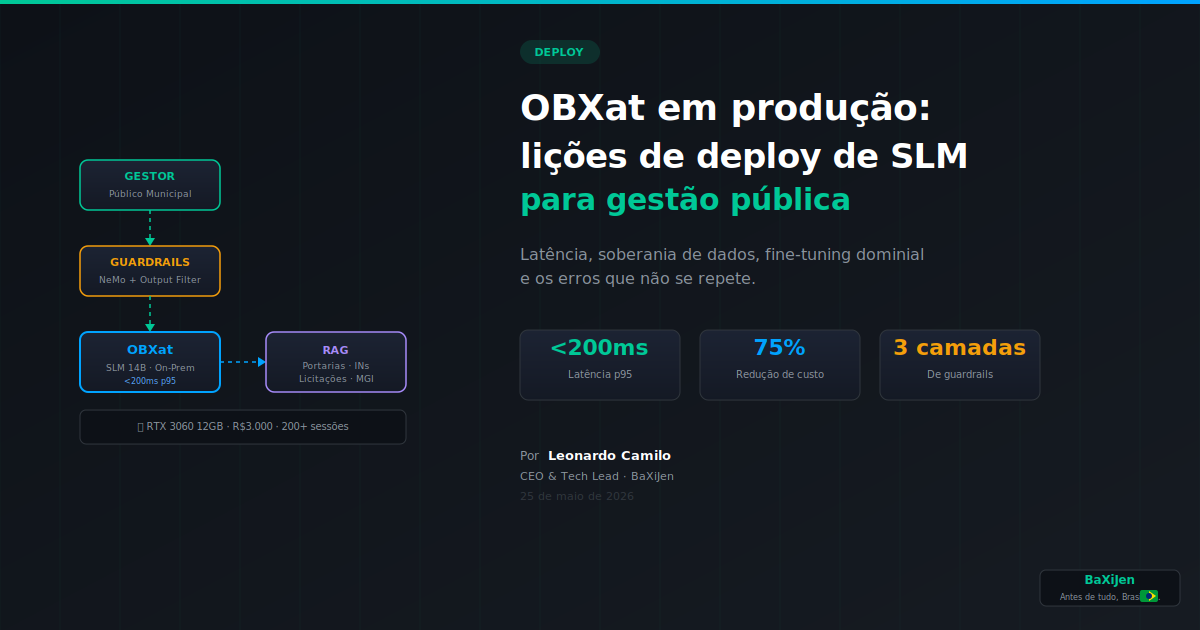
DestaqueO que aprendemos colocando um Small Language Model no front de atendimento ao gestor público. Latência, soberania de dados, fine-tuning dominial e os erros que não se repete.
 Destaque
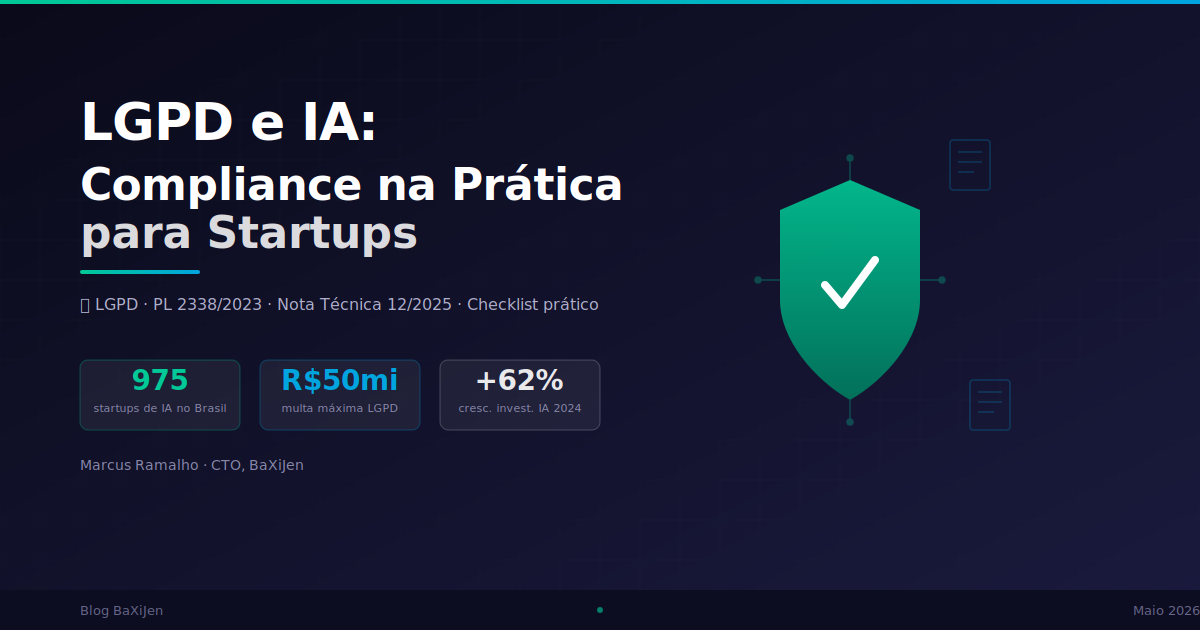
DestaqueO Brasil tem mais de 975 startups de IA, investimentos crescendo 62% ao ano, e dois marcos regulatórios que vão mudar o jogo: a LGPD em plena vigência e o PL 2338/2023 prestes a ser aprovado. Este post detalha como uma startup de IA pode estruturar compliance de privacidade de dados sem travar a operação, com base na Nota Técnica 12/2025 da ANPD, nos requisitos do PL 2338 e em casos práticos de mercado.
 Destaque
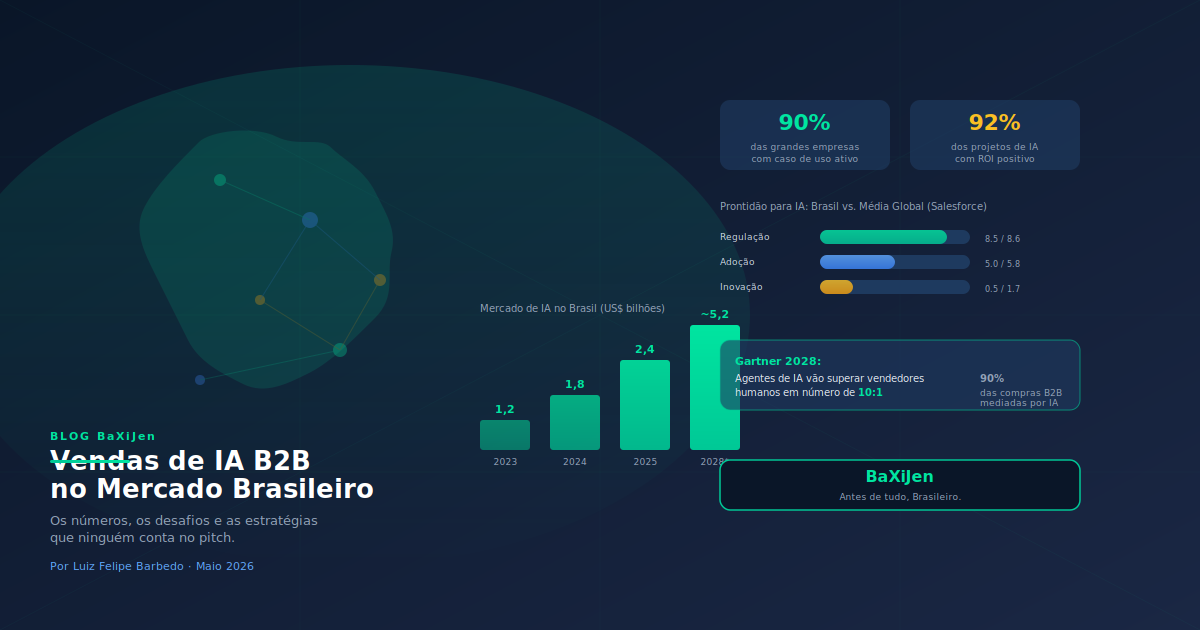
DestaqueO mercado de IA no Brasil ultrapassou US$ 2,4 bilhões em 2025, com crescimento de 18,5% ao ano. Mas vender IA B2B no país é muito diferente de vender SaaS tradicional. Analisamos dados do IDC, Gartner e Salesforce para mapear as oportunidades, os gargalos de adoção, o impacto da LGPD e o que diferencia uma startup de IA que fecha contratos de uma que não passa do pilotinho.
 Destaque
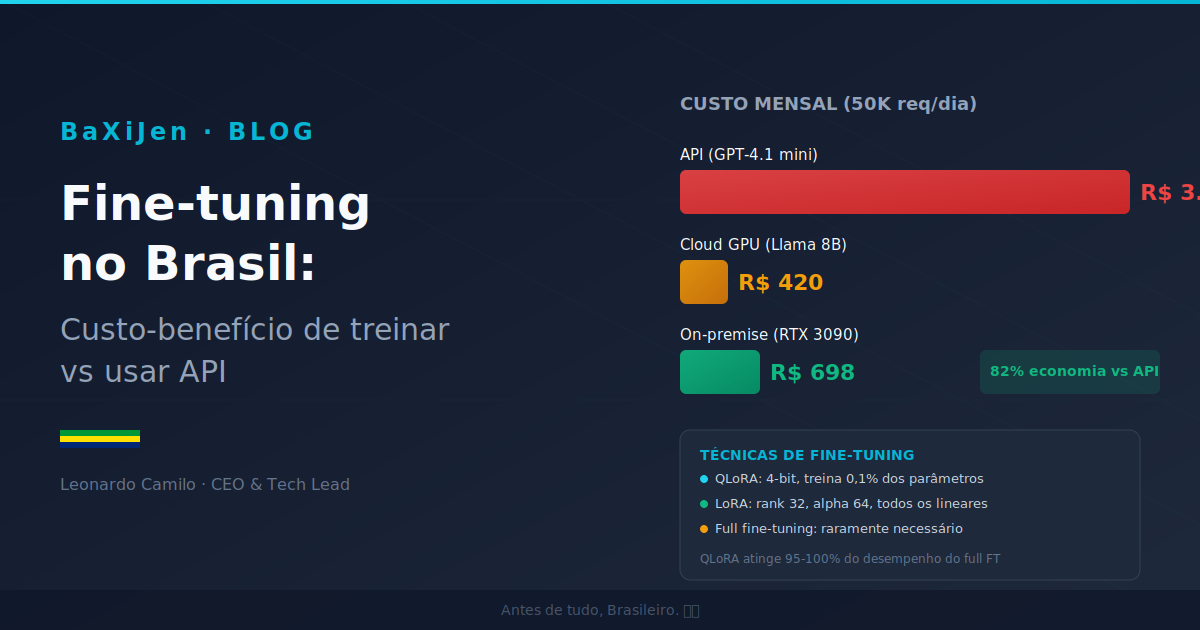
DestaqueQuanto custa, de verdade, fine-tunar um modelo de linguagem no Brasil? Comparamos API (OpenAI, Google), cloud GPU (Together AI, RunPod) e on-premise com hardware nacional, com números reais em reais. Incluímos análise LGPD, break-even por volume e um framework de decisão para empresas brasileiras escolherem o caminho certo.
 Destaque
DestaqueA maioria dos pipelines de RAG falha na hora de recuperar informação, não na geração. Analisamos por que naive RAG quebra em produção e apresentamos as arquiteturas que realmente funcionam: chunking hierárquico, busca híbrida BM25+vetorial, reranking com cross-encoder e avaliação com RAGAS, com números e benchmarks reais.
 Destaque
DestaqueAnálise fundamentada sobre os desafios reais de operar agentes autônomos em produção, com dados de outage da OpenAI, research da LangChain sobre observabilidade de agentes e lições da BaXiJen operando a Milena em múltiplos canais desde 2026.
 Destaque
DestaqueUm ensaio sobre IA, Big Techs e dialética do poder, reafirmando por que a BaXiJen existe: para quebrar a dependência digital do Brasil e devolver autonomia a quem deveria ser senhor, não servo, da tecnologia.
 Destaque
DestaqueAnálise do PBIA (R$ 23 bi), da Resolução ANPD 19/2024 sobre transferência internacional de dados, e do caso francês (€ 109 bi) para argumentar por que dependência de infraestrutura estrangeira de IA é risco operacional e regulatório real para organizações brasileiras.
 Destaque
DestaqueAnálise do paper da NVIDIA Research (Belcak et al., 2026), do estudo do ACL (Wang et al., 2026) e da experiência da BaXiJen para argumentar que Small Language Models são mais adequados, mais econômicos e mais soberanos para agentes em produção do que LLMs generalistas.
Conteúdo técnico sobre IA, soberania e produto.
Análises com dados reais, papers acadêmicos e lições de produção. Sem spam, sem buzzword. Um email por semana.