Context Engineering: O Novo Prompt Engineering para Agentes de Produção
Prompt engineering era suficiente quando LLMs recebiam uma instrução e geravam uma resposta. Mas agentes operam em loops de dezenas de turnos, acumulam histórico, invocam ferramentas e consultam fontes externas. Gerenciar o que entra na janela de contexto em cada passo se tornou a alavanca número 1 de qualidade em produção. Este artigo mapeia a anatomia do context engineering, os quatro modos de falha de contexto, as estratégias de write, select, compress e isolate, e como aplicá-las em agentes brasileiros de produção.
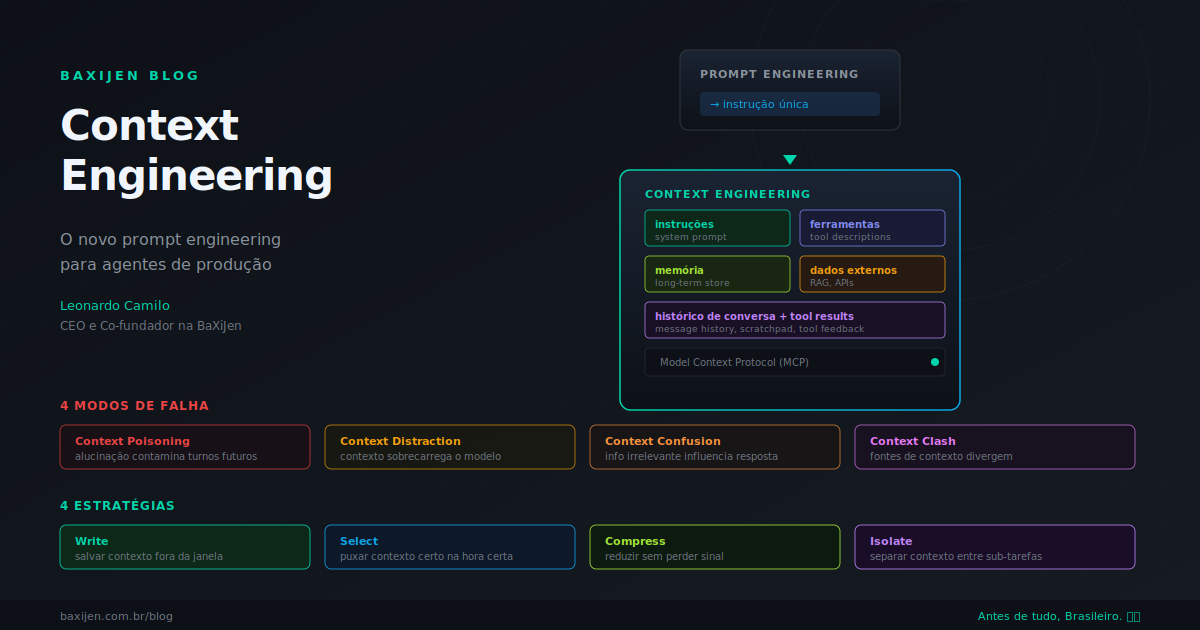
Em junho de 2025, Andrej Karpathy publicou um post que redesenhou o vocabulário da engenharia de IA: "I'm a big fan of the term 'context engineering' over 'prompt engineering'. The art and science of filling the context window with just the right information for the next step." A frase viralizou porque nomeava algo que todo time de produção já sentia: o prompt não é o problema. O problema é o que está dentro da janela de contexto a cada turno de um agente que roda dezenas de vezes.
Prompt engineering funciona bem para tarefas de um turno: classifique este texto, resuma este documento, extraia estas entidades. Mas quando você constroi um agente que opera em loop, invoca ferramentas, consulta bases de conhecimento e mantém memória entre sessões, a instrução escrita no prompt é apenas uma fração do que o modelo recebe. O restante é contexto dinâmico: resultados de ferramentas, histórico de conversa, documentos recuperados, memórias de longo prazo, permissões do usuário, configurações de runtime. E cada token adicional nessa janela tem custo: atenção diluída, latência maior, fatura inchada e, em algum ponto, degradação de performance.
Este artigo mapeia por que context engineering substituiu prompt engineering como disciplina central de produção, quais são os modos de falha que surgem quando o contexto é mal gerenciado, as quatro estratégias fundamentais (write, select, compress, isolate) e como aplicá-las na prática para agentes que servem usuários brasileiros.
1. Por que prompt engineering não basta para agentes
A diferença fundamental entre prompt engineering e context engineering é o escopo do que cada disciplina otimiza. Prompt engineering se concentra em escrever a instrução certa: o system prompt, os exemplos few-shot, o formato de saída. Context engineering se concentra em curar o conjunto completo de tokens que o modelo recebe em cada inferência, incluindo instruções, histórico de mensagens, descrições de ferramentas, dados do RAG, memórias de longo prazo e feedback de tool calls.
A Anthropic definiu context engineering como "o conjunto de estratégias para curar e manter o conjunto ótimo de tokens durante a inferência do LLM, incluindo toda a informação que pode pousar ali fora dos prompts" (Anthropic, 2025). A LangChain reforça: "Context engineering is providing the right information and tools in the right format so the LLM can accomplish a task. This is the number one job of AI Engineers" (LangChain, 2025).
A razão pela qual essa distinção importa na prática é que agentes geram contexto exponencialmente. Um agente que faz 20 turnos de inferência, cada um consultando 3 ferramentas, pode acumular dezenas de milhares de tokens em poucos minutos. O modelo não tem como distinguir entre a instrução original e o ruído acumulado: tudo é tokens, tudo compete pela mesma atenção. A arquitetura transformer calcula atenção par a par (n² relações para n tokens), o que significa que dobrar o contexto mais que dobra o custo computacional de atenção (Vaswani et al., 2017, arXiv:1706.03762).
Pesquisas em benchmarks needle-in-a-haystack revelaram o fenômeno de context rot: à medida que o número de tokens na janela aumenta, a capacidade do modelo de recuperar informações com precisão diminui (Chroma Research, 2025). Não é um cliff abrupto, é uma degradação gradual. Modelos maiores toleram mais, mas nenhum é imune. A implicação prática é direta: contexto é recurso finito com retornos marginais decrescentes, e deve ser tratado como tal.
2. Os quatro modos de falha de contexto
Drew Breunig, pesquisador de context engineering, categorizou quatro modos de falha que surgem quando o contexto é mal gerenciado em agentes de produção (Breunig, 2025). Entender esses modos é essencial para diagnosticar por que um agente que funciona em demo falha em produção.
Context Poisoning: uma alucinação do modelo entra no contexto e contamina as respostas subsequentes. Se o agente afirma algo incorreto no turno 5 e essa afirmação fica no histórico, os turnos 6, 7 e 8 vão referenciar o erro como se fosse fato. O veneno se propaga porque o modelo não distingue entre informação gerada e informação verificada.
Context Distraction: o contexto cresce a ponto de sobrecarregar os padrões aprendidos no treinamento. O modelo passa a dar peso desproporcional a informações recentes no contexto em detrimento das instruções originais. É o equivalente a uma pessoa que para de ouvir o que foi pedida porque está sobrecarregada de estímulos.
Context Confusion: informações irrelevantes ou contraditórias no contexto influenciam a resposta. Um agente que recebe documentação de três versões diferentes de uma API pode gerar código que mistura sintaxes incompatíveis. O modelo não tem mecanismo nativo para dizer "essa informação é conflitante, vou ignorar".
Context Clash: partes do contexto divergem abertamente. O system prompt diz "seja conciso", mas o usuário pediu uma resposta detalhada. O RAG retornou um documento que contradiz a política do agente. Quando duas fontes de contexto conflitam, o modelo escolhe arbitrariamente, e a escolha muda a cada execução.
A Cognition, empresa que construiu o Devin, colocou de forma direta: "Context engineering is effectively the number one job of engineers building AI agents" (Cognition, 2025). Não é otimização: é requisito. Sem context engineering, agentes falham de forma silenciosa e inconsistente.
3. As quatro estratégias de context engineering
Lance Martin, da LangChain, organizou as abordagens de context engineering em quatro categorias: write, select, compress e isolate (Martin, 2025). Cada uma ataca um modo de falha diferente e juntas formam um framework completo para gerenciar contexto em agentes de produção.
3.1 Write: salvar contexto fora da janela
A primeira estratégia é persistir informações importantes fora da janela de contexto para que não sejam perdidas quando o contexto for truncado ou o agente reiniciado. A implementação mais simples é o scratchpad: um espaço de rascunho onde o agente salva planos, descobertas e estados intermediários.
A Anthropic descreveu o caso de seu agente de pesquisa multi-agente: "The LeadResearcher begins by thinking through the approach and saving its plan to Memory to persist the context, since if the context window exceeds 200,000 tokens it will be truncated and it is important to retain the plan" (Anthropic, 2025). O scratchpad pode ser implementado como uma chamada de ferramenta que escreve em arquivo, ou como um campo no objeto de estado do runtime.
Além de scratchpads intra-sessão, memórias de longo prazo permitem que agentes aprendam entre sessões. O framework Reflexion (Shinn et al., 2023, arXiv:2303.11366) introduziu a ideia de reflexões geradas após cada turno do agente e reutilizadas em sessões futuras. Generative Agents (Park et al., 2023, arXiv:2304.03442) criaram memórias sintetizadas periodicamente a partir de coleções de feedback passado. Esses conceitos foram absorvidos por produtos como ChatGPT, Cursor e Windsurf, que geram memórias de longo prazo automaticamente a partir de interações com o usuário.
3.2 Select: puxar o contexto certo para a janela
Selecionar contexto é a operação inversa de write: recuperar a informação certa no momento certo. RAG é a forma mais conhecida, mas a seleção vai além da recuperação de documentos.
Para scratchpads implementados como ferramentas, o agente lê o conteúdo fazendo uma chamada de tool. Para scratchpads no estado do runtime, o desenvolvedor escolhe quais partes do estado expor ao agente a cada passo, com granularidade fina.
Memórias de longo prazo precisam de mecanismos de seleção porque crescem sem limites. Três abordagens principais existem: seleção por similaridade semântica (recuperar memórias mais relevantes à query atual), seleção por recência (priorizar interações recentes) e seleção por importância (pesar memórias por seu impacto em decisões passadas). O framework Generative Agents combinou as três com um score composto (Park et al., 2023).
A seleção de ferramentas também é uma decisão de context engineering. Um agente com 30 ferramentas disponíveis gera 30 descrições de ferramentas no contexto a cada turno, mesmo que use apenas 2. Técnicas de tool filtering selecionam o subconjunto relevante antes de montar o prompt, economizando tokens e reduzindo confusão.
3.3 Compress: reduzir contexto sem perder sinal
Compressão é a resposta ao fato de que contexto cresce inevitavelmente em agentes de longa duração. As três técnicas principais são sumarização, truncagem seletiva e compressão de tool results.
Sumarização transforma um histórico longo em um resumo mais curto que preserva os fatos essenciais. A abordagem mais comum é sumarizar os turnos mais antigos da conversa enquanto mantém os turnos recentes intactos. OpenAI e Anthropic implementam isso nativamente em algumas APIs, mas a qualidade da sumarização varia e informações sutis podem ser perdidas.
Truncagem seletiva remove partes do contexto explicitamente: mensagens antigas do histórico, resultados de ferramentas que já foram processados, documentos do RAG que não foram citados. A diferença entre truncagem seletiva e truncagem cega é que a seletiva preserva informações referenciadas em turnos subsequentes.
Compressão de tool results é particularmente importante porque tool calls frequentemente retornam muito mais dados do que o agente precisa. Um agente que consulta uma API de transações pode receber 50 registros quando precisa de 3. A compressão pode acontecer no lado da ferramenta (filtrar antes de retornar) ou no lado do agente (sumarizar o resultado antes de colocá-lo no contexto).
3.4 Isolate: separar contexto entre sub-tarefas
A estratégia mais recente em context engineering é o isolamento: em vez de tentar gerenciar um único contexto monolítico, divida o agente em sub-agentes com contextos isolados. Cada sub-agente recebe apenas o contexto relevante para sua sub-tarefa e retorna apenas o resultado final para o agente coordenador.
A Cognition argumentou contra sistemas multi-agente genéricos, mas endossou o isolamento de contexto como prática essencial: em vez de ter múltiplos agentes se comunicando, tenha um agente que delega sub-tarefas para executores isolados e recebe apenas o resultado sintetizado (Cognition, 2025). A vantagem é que cada executor trabalha com um contexto menor e mais focado, evitando os modos de falha de distraction e confusion.
O Google publicou orientações de arquitetura para frameworks multi-agente context-aware que escalonam para produção, propondo context engineering em camadas: contexto de sistema (instruções e configurações), contexto de conversa (histórico e estado atual) e contexto de ferramenta (descrições e resultados). Cada camada é gerenciada independentemente (Google Developers Blog, 2025).
4. Aplicando context engineering em produção: o checklist
Com base nas quatro estratégias e nos modos de falha, este checklist orienta a implementação de context engineering em agentes de produção.
| Problema | Estratégia | Implementação |
|---|---|---|
| Histório cresce e degrada performance | Compress | Sumarizar turnos antigos, manter recentes intactos |
| Agente repete erro de turnos anteriores | Write + Select | Salvar correções em scratchpad, recuperar antes de decidir |
| Muitas ferramentas poluem o contexto | Select | Tool filtering dinâmico por sub-tarefa |
| Tool returns incham a janela | Compress | Filtrar campos do JSON de retorno antes de montar o prompt |
| Sub-tarefas interferem entre si | Isolate | Delegar para executores com contexto isolado |
| Memória entre sessões inexistente | Write | Persistir reflexões e preferências do usuário em store |
| Informações conflitantes no contexto | Select | Rankear fontes por confiabilidade e recência |
| Agente perde a instrução original | Compress | Manter system prompt no topo e truncar meio do histórico |
5. Context engineering para agentes brasileiros: implicações práticas
No contexto brasileiro, context engineering ganha contornos específicos que frameworks internacionais não cobrem.
Idioma e tokenização: textos em português consomem mais tokens que em inglês para o mesmo conteúdo semântico, porque tokenizers de modelos open-source são otimizados para inglês. Um documento que em inglês ocupa 2.000 tokens pode ocupar 2.800 em português. Isso comprime a janela útil e torna compressão e seleção ainda mais críticas.
RAG em documentos legais: agentes que servem gestores públicos consultam Diário Oficial, portarias, leis e normas. Esses documentos são longos, repetitivos e frequentemente ambíguos. Context engineering aqui exige chunking semântico que respeita a estrutura legal (artigos, parágrafos, incisos) e seleção que prioriza o documento mais recente quando há conflito.
MCP como alavanca de context engineering: o Model Context Protocol (MCP) padroniza como agentes acessam fontes externas. Em vez de colocar descrições de 30 ferramentas no prompt, o agente descobre ferramentas via MCP apenas quando precisa delas. Isso é context engineering por design: o contexto é montado sob demanda, não pré-carregado.
LGPD e contexto: a LGPD impõe que dados pessoais não sejam retidos além do necessário. Context engineering aqui vira compliance engineering: a mesma sumarização que reduz tokens pode anonimizar dados pessoais, e a mesma seleção que prioriza contexto relevante pode excluir dados sensíveis que não são necessários para a tarefa atual.
6. De prompt a contexto: a mudança de mentalidade
A transição de prompt engineering para context engineering não é uma substituição, é uma expansão. Prompt engineering continua sendo a disciplina de escrever instruções claras e bem estruturadas. Context engineering absorve o prompt como um dos componentes do contexto e adiciona a responsabilidade de gerenciar todos os outros: histórico, ferramentas, dados, memória, permissões.
A mudança de mentalidade é de "o que eu escrevo no prompt?" para "qual é o estado completo do contexto neste turno e ele maximiza a chance de o modelo fazer a coisa certa?". Essa pergunta se aplica a cada turno de um agente em loop, não apenas ao prompt inicial.
Para times que estão construindo agentes de produção, a recomendação prática é: comece auditando o que está na janela de contexto do seu agente no pior caso (histórico longo, muitas ferramentas, RAG extenso). Se o total ultrapassa 50% da janela máxima do modelo, você precisa de context engineering. Se ultrapassa 75%, você precisa urgentemente.
O futuro dos agentes de produção não é determinado pelo modelo mais capaz, mas pelo time que melhor gerencia o contexto que alimenta esse modelo. Context engineering é essa disciplina.
Referências
- Anthropic. (2025). Effective context engineering for AI agents. Anthropic Engineering Blog.
- Breunig, D. (2025). How contexts fail and how to fix them. dbreunig.com.
- Cognition AI. (2025). Don't build multi-agents. cognition.ai/blog.
- Google Developers Blog. (2025). Architecting efficient context-aware multi-agent framework for production.
- Karpathy, A. (2025). Post on context engineering. X (Twitter), @karpathy.
- LangChain. (2025). Context engineering in agents. LangChain Documentation.
- Martin, L. (2025). Context engineering for agents. rlancemartin.github.io.
- Park, J. S., O'Brien, J. C., Cai, C. et al. (2023). Generative Agents: Interactive Simulacra of Human Behavior. arXiv:2304.03442.
- Shinn, N., Cassano, F., Labash, A. et al. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning. arXiv:2303.11366.
- Vaswani, A., Shazeer, N., Parmar, N. et al. (2017). Attention Is All You Need. arXiv:1706.03762.
Quer construir IA soberana?
Fale com a BaXiJen e descubra como agentes autônomos podem transformar sua operação.
Fale conoscoNewsletter BaXiJen
Conteúdo técnico sobre IA, soberania e produto.
Análises com dados reais, papers acadêmicos e lições de produção. Sem spam, sem buzzword. Um email por semana.