Knowledge Graphs para Agentes de IA: Estruturando Contexto Além do RAG
RAG resolve busca, mas não resolve entendimento. Quando agentes de IA precisam raciocinar sobre relações, rastrear mudanças temporais e responder perguntas multi-hop, knowledge graphs oferecem o que embeddings não conseguem: estrutura, proveniência e raciocínio. Este artigo mapeia por que RAG puro quebra em produção, como GraphRAG e knowledge graphs temporais resolvem essas falhas, e qual arquitetura faz sentido para agentes operando em português no contexto brasileiro.
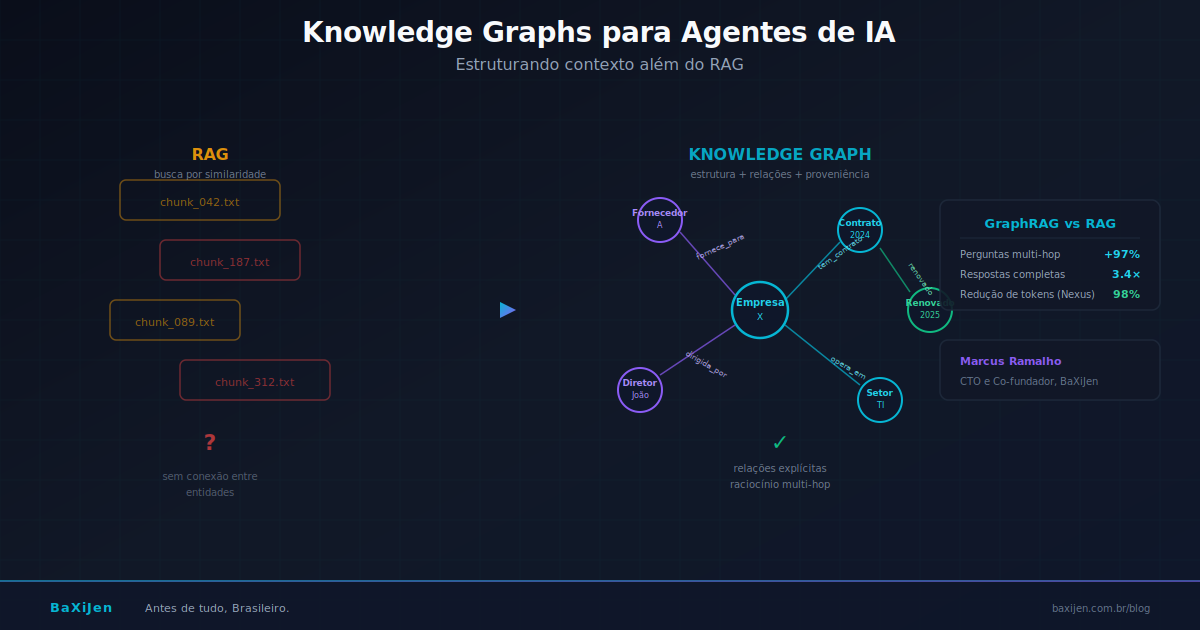
Você implementou RAG. Indexou documentos em embeddings, colocou num vector store, conectou ao LLM. Funciona para busca semântica: o usuário pergunta algo, o sistema recupera os chunks relevantes, o modelo responde. Mas aí seu agente precisa responder "quais fornecedores do setor público que forneceram serviços de TI em 2024 também tiveram contratos renovados em 2025?". O RAG recupera pedaços de texto sobre fornecedores, contratos e TI. Mas não consegue juntar as relações entre eles. Não sabe que fornecedor A está conectado a contrato B, que foi renovado em data C. Porque embeddings preservam similaridade semântica, não estrutura relacional.
Esse é o limite fundamental do RAG para agentes de IA: ele resolve busca, mas não resolve entendimento. E agentes que operam em produção precisam de entendimento. Precisam saber não apenas "que documento fala sobre X", mas "como X se relaciona com Y, quando essa relação mudou, e por que".
O artigo de Edge et al. (2024), From Local to Global: A Graph RAG Approach to Query-Focused Summarization (Microsoft Research), demonstrou que GraphRAG supera RAG tradicional em 97% das perguntas que exigem raciocínio multi-hop sobre dados narrativos. A diferença não é incremental. É estrutural.
Este artigo mapeia por que RAG puro quebra em produção, como knowledge graphs e GraphRAG resolvem essas falhas, quais ferramentas e arquiteturas estão disponíveis em 2026, e o que faz sentido para agentes operando em português no contexto brasileiro.
1. Os limites estruturais do RAG para agentes
RAG é a arquitetura mais adotada para dar contexto a LLMs. O fluxo é conhecido: chunking, embedding, indexação em vector store, retrieval por similaridade, geração condicionada nos chunks recuperados. Funciona bem para perguntas factuais diretas. Mas três limites estruturais aparecem quando agentes precisam ir além da busca.
1.1 Chunking destrói estrutura relacional
O processo de dividir documentos em chunks para embedding é uma aproximação necessária, mas perde a estrutura original. Um contrato que referencia uma cláusula em outro documento, uma regulamentação que altera uma lei anterior, uma empresa que é subsidiária de outra: essas relações existem entre entidades, não dentro de um pedaço de texto.
O estudo de Han et al. (2025), RAG vs. GraphRAG: A Systematic Evaluation and Key Insights (arXiv:2502.11371), comparou RAG e GraphRAG em seis categorias de perguntas. Em perguntas que exigem conectar informações de múltiplas fontes, GraphRAG obteve 3.4 vezes mais respostas completas que RAG tradicional. A diferença aumenta exponencialmente com a complexidade relacional do domínio.
1.2 Embeddings não capturam relações
Embeddings transformam texto em vetores de alta dimensão onde proximidade geométrica indica similaridade semântica. "João é diretor da Empresa X" e "Maria é diretora da Empresa Y" ficam próximos no espaço vetorial. Mas a relação "é diretor de" não é representada. Um agente que precisa responder "quem são os diretores de empresas do setor X?" não encontra essa estrutura no vector store. Ele encontra chunks que mencionam diretores e empresas, mas precisa inferir a relação a partir do texto, sem garantia de consistência.
1.3 RAG é stateless por design
Cada query RAG começa do zero. O sistema recupera chunks relevantes, o modelo gera uma resposta, e o contexto é descartado. Para um chatbot simples, isso é aceitável. Para um agente que mantém estado, rastreia mudanças temporais e precisa responder perguntas como "o que mudou desde a última vez que verifiquei?", a ausência de memória relacional é um bloqueio. O agente não sabe que "Empresa X era cliente" e "Empresa X encerrou contrato em março" são eventos relacionados sobre a mesma entidade em momentos diferentes.
2. Knowledge graphs: o que são e por que importam para agentes
Knowledge graphs (grafos de conhecimento) são representações estruturadas de entidades e suas relações. Em vez de armazenar texto como chunks, um knowledge graph armazena triplas: (sujeito, predicado, objeto). "João é diretor da Empresa X" vira (João, é_diretor_de, Empresa X). "Empresa X fornece serviços de TI" vira (Empresa X, fornece, Serviços de TI). A estrutura permite consultas relacionais, raciocínio sobre caminhos e inferência de conexões implícitas.
2.1 Tipos de knowledge graphs
Baseados em ontologia (ex: DBpedia, Wikidata): definem um schema formal de tipos e relações, permitem inferência lógica, mas exigem curadoria especializada e são caros de manter.
Baseados em extração automática (ex: Microsoft GraphRAG): usam LLMs para extrair entidades e relações de texto não estruturado, gerando grafos dinâmicos sem schema pré-definido. São mais flexíveis, mas podem conter ruído e inconsistência.
Temporais (ex: Graphiti/Zep): rastreiam mudanças nas relações ao longo do tempo, mantendo proveniência e versões. Essenciais para agentes que precisam entender não apenas "o que é verdade", mas "quando se tornou verdade" e "quando deixou de ser".
Híbridos: combinam estrutura ontológica com extração automática, permitindo tanto precisão formal quanto flexibilidade para incorporar novos domínios.
2.2 GraphRAG: onde RAG encontra knowledge graphs
GraphRAG, formalizado por Edge et al. (2024) na Microsoft Research, é a abordagem que combina RAG com knowledge graphs. O processo:
- Indexação: o texto é processado por um LLM que extrai entidades e relações, construindo um grafo
- Comunidades: algoritmos de detecção de comunidades (como Leiden) identificam clusters de entidades relacionadas
- Resumos: cada comunidade recebe um resumo gerado por LLM, criando hierarquia
- Consulta: perguntas são respondidas combinando buscas locais (entidades específicas) e globais (resumos de comunidades)
O resultado é que perguntas que exigem síntese de múltiplas fontes são respondidas com coerência, porque o grafo preserva a estrutura relacional que o chunking destrói.
3. Ferramentas e frameworks disponíveis em 2026
3.1 Neo4j + LLM Graph Builder
Neo4j é o banco de dados de grafos mais adotado em produção para aplicações de IA. O LLM Graph Builder (open source, 4.700+ stars no GitHub) permite extrair knowledge graphs de texto não estruturado usando LLMs e armazenar diretamente no Neo4j. A integração com LangChain e LlamaIndex facilita a construção de pipelines GraphRAG end-to-end.
Em abril de 2026, Neo4j anunciou parceria com Google Cloud para lançar uma knowledge layer para sistemas agentic, posicionando o grafo como a camada semântica entre dados brutos e agentes autônomos. A movimentação é sintomática: o mercado reconhece que agentes precisam de mais do que embeddings.
3.2 Graphiti (Zep): knowledge graphs temporais para agentes
Graphiti é um framework open source (Apache 2.0, 27.000+ stars no GitHub) desenvolvido pela Zep para construir knowledge graphs temporais em tempo real. A diferença chave em relação a knowledge graphs estáticos: Graphiti rastreia quando fatos se tornam verdadeiros, quando deixam de ser, e mantém proveniência completa da origem dos dados.
Para agentes de IA, isso é crítico. Um agente de suporte que precisa saber "este cliente ainda é premium?" não busca em um grafo estático. Busca em um grafo temporal que sabe que o cliente era premium de janeiro a março, depois cancelou, depois reativou em maio. A versão mais recente, graphiti-core v0.29.1, registra 178.000 downloads semanais no PyPI.
3.3 Pinecone Nexus: compilação de conhecimento para agentes
Em junho de 2026, a Pinecone anunciou o Nexus, descrito como um knowledge engine para agentes. A proposta central é mover o trabalho de raciocínio do tempo de inferência para um estágio de compilação: o sistema processa dados brutos uma vez, gera artefatos de conhecimento otimizados por tarefa, e serve esses artefatos para agentes em formato estruturado.
O benchmark interno da Pinecone mostra que uma tarefa de análise financeira que consumia 2,8 milhões de tokens com RAG tradicional foi completada com apenas 4.000 tokens usando Nexus. Uma redução de 98%. Os dados não foram validados em produção de clientes, mas a direção é clara: pré-compilar conhecimento estruturado é mais eficiente do que recuperar chunks brutos em tempo de inferência.
3.4 Frameworks de comparação
| Framework | Tipo | Temporal | Open Source | Caso principal |
|---|---|---|---|---|
| Neo4j + LLM Graph Builder | Grafo + extração | Não | Sim | Enterprise, dados estruturados |
| Graphiti (Zep) | Grafo temporal | Sim | Sim (Apache 2.0) | Agentes com memória e estado |
| Pinecone Nexus | Compilação de conhecimento | Parcial | Não (early access) | Agentes com tarefas repetitivas |
| Microsoft GraphRAG | Extração + comunidades | Não | Sim (MIT) | Sintese de documentos narrativos |
| LightRAG | Grafo leve incremental | Não | Sim | Prototipagem, baixo custo |
4. Arquitetura na prática: knowledge graph como camada de contexto para agentes
A arquitetura que faz sentido para agentes em produção combina knowledge graphs com RAG, não substitui um pelo outro. Cada um resolve um problema diferente.
┌──────────────────────────────────────────────────────┐
│ CAMADA DO AGENTE │
│ Agente de Consulta · Agente de Análise │
│ Agente de Compliance · Agente de Suporte │
└──────────┬───────────────────────┬───────────────────┘
│ │
Queries relacionais Busca semântica
│ │
┌──────────▼───────────┐ ┌────────▼──────────────────────┐
│ KNOWLEDGE GRAPH │ │ VECTOR STORE (RAG) │
│ Entidades e relações │ │ Embeddings + chunks │
│ Consultas estruturadas│ │ Busca por similaridade │
│ Proveniência │ │ Recuperação contextual │
└──────────┬───────────┘ └────────┬──────────────────────┘
│ │
└───────────┬───────────┘
│
Orquestração + Reranking
│
┌──────────────────────▼─────────────────────────────────┐
│ FONTE DE DADOS │
│ Documentos · APIs · Bases relacionais · Logs │
│ (extração automática via LLM + curadoria humana) │
└────────────────────────────────────────────────────────┘
O fluxo de consulta:
- O agente recebe uma pergunta e classifica o tipo: relacional (precisa de estrutura) ou factual (busca semântica basta)
- Perguntas relacionais vão ao knowledge graph: "quais fornecedores de TI tiveram contratos renovados?" retorna triplas conectando entidades
- Perguntas factuais vão ao vector store: "o que diz o artigo 5 da lei X?" retorna chunks relevantes
- Perguntas complexas usam ambos: o grafo identifica entidades e relações, o vector store recupera contexto detalhado
- Um orquestrador combina os resultados e aplica reranking por relevância e proveniência
4.1 Quando usar knowledge graph vs RAG
Use knowledge graph quando:
- O domínio tem relações ricas e explícitas entre entidades (jurídico, financeiro, organizacional)
- O agente precisa responder perguntas multi-hop (conectar A → B → C)
- Proveniência e auditabilidade são requisitos (compliance, LGPD, setor público)
- Os dados mudam ao longo do tempo e o agente precisa rastrear essas mudanças
Use RAG quando:
- O domínio é predominantemente textual e factual (documentos, artigos, manuais)
- As perguntas são diretas e não exigem raciocínio sobre relações
- A velocidade de implementação é prioritária e o domínio é simples
- Os dados são estáveis e não mudam frequentemente
Use ambos (arquitetura híbrida) quando:
- Agentes operam em domínios complexos com tanto relações quanto conteúdo textual
- Compliance exige rastreabilidade que embeddings não fornecem
- O sistema precisa evoluir de busca factual para raciocínio relacional
5. O contexto brasileiro: por que knowledge graphs são especialmente relevantes
5.1 Dados públicos brasileiros são relacionais por natureza
O setor público brasileiro opera com dados inerentemente relacionais. Diário Oficial, SICONV, Compras.gov, Transparência: cada um conecta entidades (órgãos, empresas, pessoas, contratos, licitações) através de relações explícitas e implícitas. Um agente que precisa responder "quais empresas foram multadas por órgãos do mesmo setor administrativo nos últimos 12 meses?" está fazendo uma consulta multi-hop que um vector store não consegue resolver.
A Instrução Normativa SGD/MGI nº 4/2026 estabelece políticas de compartilhamento de dados entre órgãos federais com ênfase em interoperabilidade. O pré-requisito para interoperabilidade real não é apenas conectar APIs. É ter uma camada semântica que unifique definições entre bases. Knowledge graphs são essa camada.
5.2 LGPD e rastreabilidade
A LGPD exige que qualquer tratamento de dados pessoais tenha base legal, finalidade específica e garantias de segurança. Para agentes de IA, isso se traduz em: você precisa rastrear qual dado alimentou qual decisão, de onde veio, e quando foi considerado verdadeiro. Knowledge graphs com proveniência e temporalidade resolvem isso nativamente. RAG com vector stores não rastreia proveniência de forma confiável.
5.3 Linguagem e ambiguidade em português
O português brasileiro é mais ambíguo que o inglês em muitas construções sintáticas. "Empresa X foi condenada" pode significar condenação judicial, condenação ética, ou condenação de uma proposta. Knowledge graphs resolvem ambiguidade porque representam relações explicitamente: (Empresa X, foi_condenada_judicialmente_por, TRF3) elimina a ambiguidade que embeddings preservam.
6. O que fazer na segunda-feira
Se você está construindo agentes de IA para o mercado brasileiro, três passos concretos:
-
Audite suas perguntas de negócio: liste as perguntas que seus agentes precisam responder. Classifique cada uma em factual (RAG resolve) ou relacional (precisa de knowledge graph). Se mais de 30% são relacionais, você precisa de um grafo.
-
Comece com GraphRAG sobre sua base documental: use o Microsoft GraphRAG (open source) ou Neo4j LLM Graph Builder para extrair um knowledge graph do seu corpus existente. Não construa o schema à mão. Deixe o LLM extrair entidades e relações, depois refine com curadoria humana nas entidades mais importantes.
-
Adicione temporalidade: se seus dados mudam ao longo do tempo (contratos, status de clientes, regulamentações), implemente Graphiti ou similar para rastrear versões. Um agente que não sabe quando um fato se tornou verdade não pode operar em produção com confiança.
Referências
- Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Truitt, S., & Metropolitansky, D. (2024). From Local to Global: A Graph RAG Approach to Query-Focused Summarization. Microsoft Research. arXiv:2404.16130.
- Han, H., Ma, L., Wang, Y., Shomer, H., et al. (2025). RAG vs. GraphRAG: A Systematic Evaluation and Key Insights. arXiv:2502.11371.
- Yuan, X., Liu, Y., Di, S., Wu, S., Zheng, L., Meng, R., Chen, L., Zhou, X., & Yu, J. (2025). A Pilot Empirical Study on When and How to Use Knowledge Graphs as Retrieval Augmented Generation. arXiv:2502.20854.
- Tomczak, J. M. et al. (2025). Knowledge Graph-extended Retrieval Augmented Generation for Question Answering. arXiv:2504.08893.
- Graphiti: Build Real-Time Knowledge Graphs for AI Agents. Zep, 2025. GitHub repository, 27.000+ stars. Apache License 2.0.
- Pinecone (2026). Nexus: A Knowledge Engine for Agentic AI. Announced June 2026.
- Neo4j (2026). A Knowledge Layer for Your Agentic Systems on Google Cloud. April 2026.
- VentureBeat (2026). The RAG Era Is Ending for Agentic AI. Q1 2026 Pulse Survey.
- Trantor (2026). Knowledge Graphs for Enterprise AI: Beyond RAG in 2026.
- Brasil. Instrução Normativa SGD/MGI nº 4, de 14 de janeiro de 2026. Diário Oficial da União.
Quer construir IA soberana?
Fale com a BaXiJen e descubra como agentes autônomos podem transformar sua operação.
Fale conoscoNewsletter BaXiJen
Conteúdo técnico sobre IA, soberania e produto.
Análises com dados reais, papers acadêmicos e lições de produção. Sem spam, sem buzzword. Um email por semana.