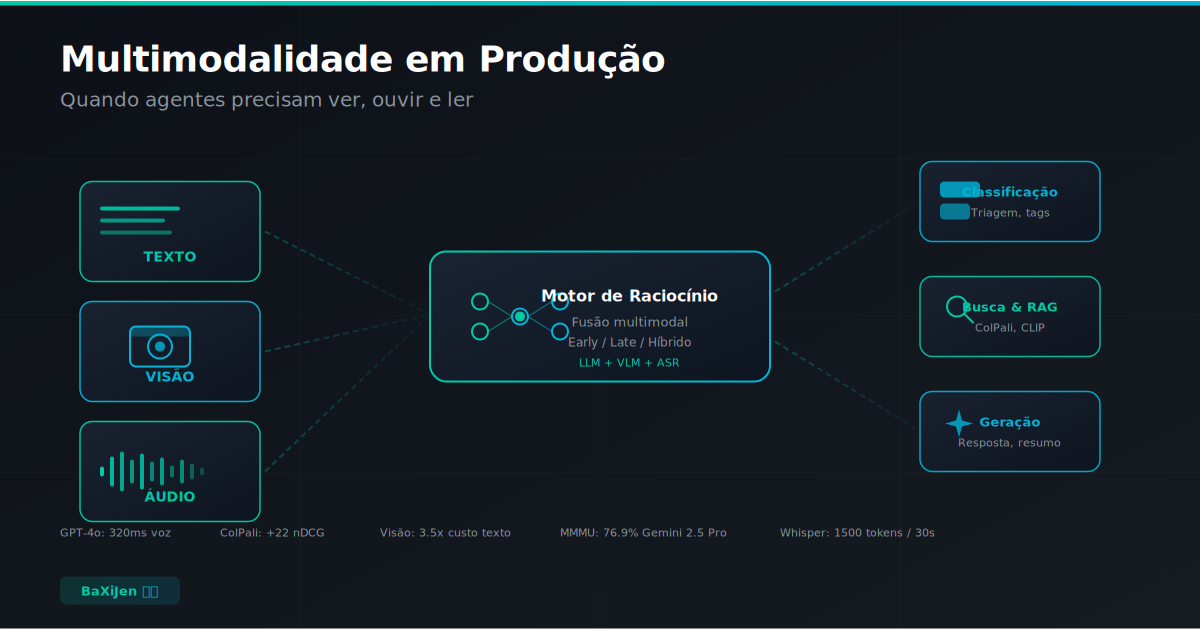
Multimodalidade em Produção: Quando Agentes Precisam Ver, Ouvir e Ler
Em 2026, agentes de IA deixaram de ser apenas text-in/text-out. GPT-4o processa áudio em tempo real com latência abaixo de 300ms, Gemini 2.5 Pro raciocina sobre imagens e vídeo, e o benchmark MMMU avalia modelos em 30 disciplinas visuais. Este artigo analisa como arquitetar sistemas multimodais em produção: os trade-offs de late-fusion vs. early-fusion, o custo real de pipelines com visão, os desafios de RAG multimodal e por que o Brasil tem casos de uso que o Vale do Silício ainda não enxergou.
Multimodalidade em Produção: Quando Agentes Precisam Ver, Ouvir e Ler
Em outubro de 2024, a OpenAI demonstrou o GPT-4o resolvendo um problema de matemática ao olhar uma foto tirada pelo usuário em tempo real, conversando por voz com latência média de 320 milissegundos (OpenAI, 2024). Poucos meses depois, o Google colocou o Gemini 2.5 Pro no topo do benchmark MMMU com 76,9% de acurácia em raciocínio multimodal across 30 disciplinas, incluindo medicina, engenharia e artes visuais (Yue et al., 2024). O Claude 3.5 Sonnet, da Anthropic, passou a interpretar capturas de tela e diagramas técnicos com precisão que rivaliza com análise humana especializada.
A fronteira de IA mudou. Modelos não são mais apenas text-in, text-out. Eles veem, ouvem e leem simultaneamente, abrindo uma categoria de aplicações que era teórica até 2024. Mas colocar multimodalidade em produção é um problema de engenharia fundamentalmente diferente de rodar um LLM de texto. Latência, custo, armazenamento e avaliação ganham dimensões novas quando a entrada pode ser uma imagem de 10 megapixels, um clipe de áudio de 30 segundos ou um PDF com 47 tabelas.
Este artigo analisa o estado da arte em junho de 2026: as arquiteturas que funcionam em produção, os trade-offs entre fusão precoce e tardia, o custo real de pipelines multimodais, os desafios de RAG com visão e por que o Brasil tem casos de uso que o Vale do Silício ainda não enxergou.
O que muda quando seu agente precisa ver
Um agente de texto puro tem um pipeline simples: string de entrada, inferência, string de saída. O token é a unidade atômica. Adicionar visão explode essa simplicidade. Uma imagem de 1024x1024 pixels, quando processada por um vision encoder como o ViT-L/14, gera aproximadamente 1.024 tokens visuais que precisam ser integrados ao contexto textual (Radford et al., 2021). Um PDF de 20 páginas, se processado visualmente pelo ColPali, produz 20.000 tokens visuais (Faysse et al., 2024). Um clipe de áudio de 30 segundos codificado pelo Whisper Large v3 consome cerca de 1.500 tokens (OpenAI, 2023).
Isso tem três implicações diretas para produção:
Primeira: o contexto explode. Um agente que recebe um documento escaneado de 50 páginas precisa de uma janela de contexto que acomode 50.000 tokens visuais mais o prompt textual mais a resposta. Modelos com 128K de contexto lidam com isso, mas o custo de inferência escala linearmente com o número de tokens, visuais ou textuais. No GPT-4o, processar 50 páginas visuais custa aproximadamente US$ 0,38 só de input, sem contar a resposta (OpenAI, 2025). Em alto volume, isso inviabiliza use cases de baixa margem.
Segunda: a latência muda de categoria. Um LLM de texto gera 80 a 150 tokens por segundo em GPU consumer. Um modelo multimodal precisa primeiro codificar a imagem (50 a 200ms por imagem em A100), depois processar a sequência combinada de tokens visuais e textuais. O end-to-end latency de uma consulta com uma imagem no GPT-4o Vision fica em 1,5 a 3 segundos, contra 200 a 500ms para texto puro (Artificial Analysis, 2025). Em aplicações conversacionais com voz, o GPT-4o Realtime reduz isso para 320ms de média porque elimina a etapa de transcrição intermediária, mas exige WebRTC e uma arquitetura de streaming fundamentalmente diferente (OpenAI, 2024).
Terceira: a avaliação não tem padrão. Avaliar texto é relativamente trivial: ROUGE, BLEU, perplexidade, avaliação humana. Avaliar saída multimodal é um problema em aberto. O benchmark MMMU testa raciocínio com imagens em 30 disciplinas, mas não cobre áudio ou vídeo (Yue et al., 2024). O MMBench-Video avalia compreensão de vídeo com perguntas abertas, mas é pequeno e especializado (Mao et al., 2025). Não existe um equivalente do MMLU para sistemas que combinam texto, imagem e áudio simultaneamente.
Arquiteturas de fusão: early vs. late e por que importa
Quando um agente precisa processar texto e imagem juntos, existem duas estratégias arquiteturais, e a escolha determina custo, latência e qualidade.
Early fusion: o modelo nativo
Na early fusion, o modelo nasce multimodal. O GPT-4o e o Gemini 2.5 Pro são exemplos: um único transformer recebe tokens textuais, visuais e de áudio no mesmo contexto, processados por encoders especializados mas integrados em uma única passagem. A OpenAI treina o GPT-4o com pares (texto, imagem, áudio) alinhados desde o pré-treinamento, o que permite que o modelo raciocine cross-modal sem etapas intermediárias (OpenAI, 2024).
A vantagem é qualidade. O modelo aprende relações entre modalidades durante o treino, não em tempo de inferência. Quando o GPT-4o olha um gráfico de barras e responde uma pergunta sobre ele, não precisa primeiro descrever o gráfico em texto: ele raciocina diretamente sobre a representação visual.
A desvantagem é lock-in e custo. Early fusion exige treinar ou usar um modelo proprietário caro. Não é possível plugar um Llama 3.2 e adicionar visão sem fine-tuning significativo. O custo por token visual no GPT-4o é US$ 0,01 por imagem de baixa resolução e US$ 0,0175 por imagem de alta resolução (OpenAI, 2025). Em pipeline de alto volume, isso limita viabilidade.
Late fusion: encoders separados + LLM
Na late fusion, cada modalidade é processada por um encoder especializado e os resultados são combinados em tempo de inferência. O texto vai para o LLM. A imagem vai para um vision encoder como CLIP, que produz um embedding vetorial (Radford et al., 2021). O áudio vai para um modelo ASR como Whisper, que transcreve para texto (OpenAI, 2023). O LLM então recebe texto + descrição da imagem + transcrição do áudio e raciocina sobre tudo.
A vantagem é flexibilidade e custo. Cada componente pode ser open-source e rodar on-premise. O CLIP ViT-L/14 roda em uma RTX 3060 com 12GB e gera embeddings em 30ms por imagem. O Whisper Large v3 transcreve em tempo real em CPU. O LLM pode ser um Qwen 2.5 7B rodando localmente. O custo total por consulta fica abaixo de US$ 0,001 (Hugging Face, 2025).
A desvantagem é perda de informação. Quando o CLIP codifica uma imagem em um embedding de 768 dimensões, ele comprime informações visuais em um vetor denso. Detalhes finos como texto dentro da imagem, posições espaciais precisas e relações entre objetos podem se perder. O LLM recebe uma descrição comprimida, não a imagem original. Isso funciona para classificação e busca, mas quebra em tarefas que exigem raciocínio visual fino, como ler um gráfico ou interpretar um diagrama técnico.
A fronteira híbrida: ColPali e visão como primeiro cidadão
O ColPali (Faysse et al., 2024), apresentado no ICLR 2025, propõe uma abordagem que está se tornando o padrão para RAG multimodal com documentos. Em vez de extrair texto de PDFs via OCR e depois indexar, o ColPali processa cada página do documento como uma imagem, usando um modelo vision-language (Qwen2-VL) para gerar embeddings visuais page-level. A recuperação acontece por similaridade entre o embedding da query textual e os embeddings visuais das páginas, sem OCR intermediário.
Os resultados são expressivos. No benchmark ViDoRe, que avalia retrieval de documentos visuais, o ColPali supera pipelines tradicionais de OCR + text embedding em 22 pontos de nDCG (Faysse et al., 2024). A Microsoft já oferece uma solução de RAG multimodal baseada em ColPali como referência (Microsoft, 2025). Para documentos brasileiros como Diário Oficial, formulários scaneados e laudos técnicos, onde o layout visual carrega tanta informação quanto o texto, essa abordagem é particularmente relevante.
RAG multimodal: além da busca por texto
RAG tradicional recupera pedaços de texto por similaridade semântica. RAG multimodal recupera contextos que podem ser imagens, tabelas, diagramas, áudio ou vídeo, e os entrega ao LLM como grounding para a resposta.
O paper Multi-RAG (Mao et al., 2025), da Johns Hopkins University e do Army Research Laboratory, propõe um sistema que integra ASR (Whisper), VLMs (Qwen2-VL) e LLMs em um pipeline unificado para compreensão de vídeo. O sistema segmenta vídeo em cenas, transcreve o áudio, extrai frames visuais e indexa tudo em uma base vetorial compartilhada. Quando o usuário faz uma pergunta, o Multi-RAG recupera os trechos mais relevantes across modalidades e os entrega ao LLM como contexto multimodal. No benchmark MMBench-Video, o Multi-RAG supera Video-LLMs dedicados como Video-LLaVA e VideoChatGPT, utilizando menos recursos e menos dados de entrada (Mao et al., 2025).
A OpenAI publicou um cookbook detalhando como usar embeddings CLIP para RAG multimodal com GPT-4 Vision, contornando o problema da descrição textual lossy: em vez de captionar a imagem e buscar pelo texto da caption, o sistema busca diretamente por similaridade no espaço visual do CLIP (OpenAI, 2025). Isso preserva informações visuais que seriam perdidas na tradução para texto.
O projeto MissRAG, aceito no ICCV 2025, aborda um problema prático que todo pipeline multimodal encontra: modalidade faltante. Nem toda consulta tem imagem associada. Nem todo documento tem áudio. O MissRAG propõe um framework que mantém qualidade de resposta mesmo quando uma das modalidades está ausente, usando estratégias de imputação e projeção cross-modal (Aimagelab, 2025).
Os 12 mandamentos do RAG multimodal em produção
A Augment Code publicou um guia com 12 melhores práticas para sistemas de RAG multimodal em produção (Augment Code, 2025). As cinco mais críticas:
- Indexação multimodal separada: manter índices vetoriais separados para texto e imagem, com schemas de metadados que permitam filtrar por modalidade. Isso reduz ruído na recuperação.
- Chunking visual: segmentar imagens grandes em patches sobrepostos antes de embeddar, similar ao chunking de texto. Cada patch vira um item indexável.
- Re-ranking cross-modal: após a recuperação inicial, aplicar um re-ranker que considere coerência entre modalidades, não apenas similaridade individual.
- Cache de embeddings visuais: re-embeddar imagens é caro. Cache com TTL de 24 a 72 horas reduz custo em pipelines de alto volume.
- Fallback graceful: se o vision encoder falhar ou retornar baixa confiança, cair para text-only RAG. O sistema não pode travar porque uma imagem não carregou.
Custos reais: texto vs. visão vs. áudio em produção
Tabela 1 compara o custo de inferência por modalidade em três cenários: API proprietária (GPT-4o), modelo open-source em GPU dedicada (Qwen2-VL 7B em A100) e edge (Phi-4 em NPU local).
| Cenário | Texto (1K tokens) | Imagem (1 imagem 1024x1024) | Áudio (30s) | Observação |
|---|---|---|---|---|
| GPT-4o API | US$ 0,005 | US$ 0,0175 | US$ 0,006 | Preço de input, jan/2026 |
| Qwen2-VL 7B (A100) | ~US$ 0,0008 | ~US$ 0,002 | ~US$ 0,001 | Custo de cloud GPU amortizado |
| Phi-4 (NPU local) | US$ 0 | US$ 0 | US$ 0 | Custo de hardware já pago |
Os números revelam que visão é 3,5x mais cara que texto no GPT-4o e 2,5x mais cara no Qwen2-VL. Em pipelines que processam centenas de imagens por segundo, a diferença entre early fusion (API proprietária) e late fusion (encoders open-source) determina viabilidade de negócio.
Para um caso de uso brasileiro concreto: uma prefeitura que queira indexar 10 mil documentos escaneados do Diário Oficial para consulta cidadã. Usando GPT-4o Vision para processar cada página, o custo de indexação seria aproximadamente US$ 4.375 (250 mil páginas x US$ 0,0175). Usando ColPali com Qwen2-VL 7B em uma RTX 3060 local, o custo de GPU seria cerca de US$ 50 de eletricidade para processar tudo em aproximadamente 8 horas. A diferença é dois pedidos de grandeza.
Casos de uso que o Vale do Silício não enxerga
A maior parte da inovação em multimodalidade vem de laboratórios americanos e chineses, que pensam em aplicações para mercados onde a infraestrutura é homogênea. O Brasil tem problemas que criam demanda por multimodalidade em condições que os grandes laboratórios não consideram.
Saúde pública em regiões de baixa conectividade. O SUS opera em um país continental onde muitos postos de saúde não têm conexão estável. Um agente multimodal que funcione em edge, processando fotos de lesões dermatológicas e áudio de descrição do paciente offline, pode apoiar triagem em locais onde um dermatologista visita uma vez por mês. Um estudo publicado na Springer em 2025 analisou a adoção de IA na saúde brasileira e destacou que a dupla cobertura público-privada combinada com a carga tripla de doenças (crônicas, infecciosas e violência) posiciona a IA como ferramenta crítica (Springer, 2025). Modelos multimodais que combinam imagem clínica, áudio do paciente e dados laborariais textuais são o caso ideal.
Agricultura de precisão com visão. O agronegócio brasileiro responde por aproximadamente 25% do PIB nacional. Fazendas em Mato Grosso e Goiás geram volumes massivos de dados não-estruturados: fotos de lavouras para detecção de pragas, áudio de colheitadeiras para diagnóstico de falhas, relatórios técnicos em PDF com tabelas e gráficos. Um agente multimodal que processe tudo isso e responda perguntas em linguagem natural, rodando on-premise por soberania de dados, é um produto que nenhuma empresa americana está construindo para o contexto brasileiro (Mattos Filho, 2025).
Gestão pública com documentos visuais. Diários Oficiais, formulários escaneados, plantas arquitetônicas, mapas de zoneamento. O setor público brasileiro produz e consome documentos que são inerentemente visuais. OCR resolve parte do problema, mas perde layout, tabelas complexas e diagramas. RAG multimodal com ColPali, rodando on-premise para cumprir LGPD, é uma necessidade real que a BaXiJen observa em conversas com órgãos públicos.
Acessibilidade. Um agente que veja (através da câmera do smartphone) e ouça (através do microfone) pode descrever o ambiente para uma pessoa com deficiência visual em tempo real, em português, com latência conversacional. A infraestrutura existe: o GPT-4o Realtime entrega isso via API. O desafio é custo, latência em redes brasileiras e o trabalho de adaptação para o contexto urbano brasileiro (calçadas irregulares, sinalização não padronizada, transporte público com áudio ambiente caótico).
Como arquitetar: um blueprint prático
Para um sistema multimodal em produção no Brasil em 2026, a arquitetura que recomendamos baseia-se em três princípios: usar early fusion quando a qualidade for crítica e o orçamento permitir, late fusion para volume e custo, e ColPali para documentos.
Camada de entrada. Um router classifica o tipo de input: texto puro vai direto ao LLM. Imagem vai ao vision encoder (CLIP para embeddings, Qwen2-VL para descrição rica). Áudio vai ao Whisper para transcrição. PDFs vão ao ColPali para indexação visual. Cada modalidade tem seu próprio microserviço, escalando independentemente.
Camada de recuperação. Índices vetoriais separados por modalidade (texto em pgvector, imagens em um índice FAISS otimizado para embeddings visuais). Re-ranking cross-modal opcional quando a consulta é ambígua. Cache de embeddings visuais com TTL de 48 horas.
Camada de raciocínio. O LLM recebe o prompt textual, os embeddings ou descrições das outras modalidades e gera a resposta. Para casos que exigem raciocínio visual fino (ler gráfico, interpretar diagrama), usar GPT-4o Vision ou Gemini 2.5 Pro via API. Para casos de classificação e busca, Qwen2-VL 7B local é suficiente.
Camada de observabilidade. Logging de latência por modalidade (tempo de encoding, tempo de recuperação, tempo de inferência). Alertas quando a latência visual excede 2 segundos. Tracking de custo por token visual vs. textual. Avaliação contínua com um conjunto de testes que inclui casos multimodais, não apenas textuais.
Os próximos 12 meses
A trajetória da multimodalidade em produção aponta para três direções em 2026 e 2027.
Modelos multimodais nativamente abertos. O Qwen2.5-VL e o Llama 3.2 Vision estão reduzindo a distância para modelos proprietários em benchmarks visuais. Quando um modelo open-source de 7B atingir 70%+ no MMMU, o custo de visão cai outra ordem de grandeza. Projeções indicam que isso acontece até o final de 2026 (Artificial Analysis, 2026).
Streaming em tempo real como padrão. O GPT-4o Realtime e o Gemini 2.5 Flash Live estão normalizando interação por voz com latência sub-segundo. Em 2027, espera-se que APIs de streaming multimodal sejam o default, não um recurso premium. A barreira para o Brasil é latência de rede: conversar com um servidor em Virginia adiciona 150 a 300ms de round-trip, inviabilizando voz em tempo real. Edge inference com SLMs multimodais é o caminho.
Avaliação padronizada. O campo precisa de um equivalente ao MMLU para sistemas multimodais integrados. O MMMU cobre visão + texto, mas não áudio. O MMBench-Video cobre vídeo, mas é pequeno. Uma iniciativa colaborativa para criar um benchmark brasileiro multimodal, com dados de saúde, agricultura e gestão pública, seria um diferencial competitivo para a pesquisa nacional.
Conclusão
Multimodalidade em produção não é um upgrade de texto: é uma mudança de categoria. O custo, a latência, a arquitetura e a avaliação ganham complexidade nova quando o agente precisa ver, ouvir e ler. Mas é exatamente essa complexidade que cria oportunidade para quem entende o contexto local. O Brasil tem documentos visuais que OCR não resolve, infraestrutura que exige edge, e casos de uso em saúde e agricultura que ninguém no Vale do Silício está construindo.
Na BaXiJen, construímos agentes que raciocinam sobre dados brasileiros, em português, com soberania. Multimodalidade é o próximo passo natural: um agente que lê um Diário Oficial escaneado, interpreta um laudo médico com imagem anexada e transcreve uma reunião em áudio, tudo no mesmo contexto, é o produto que o setor público brasileiro precisa. E é o que estamos construindo.
Referências
- Artificial Analysis (2025). GPT-4o Realtime (Dec '24): Intelligence, Performance & Price Analysis. Artificial Analysis. Disponível em: https://artificialanalysis.ai/models/gpt-4o-realtime-dec-2024
- Artificial Analysis (2026). LLM Leaderboard 2026: Compare 259 AI Models Across 247 Benchmarks. Disponível em: https://benchlm.ai/
- Augment Code (2025). Multimodal RAG Development: 12 Best Practices for Production Systems. Disponível em: https://www.augmentcode.com/guides/multimodal-rag-development-12-best-practices-for-production-systems
- Aimagelab (2025). MissRAG: Addressing the Missing Modality Challenge in Multimodal Large Language Models. ICCV 2025. GitHub: https://github.com/aimagelab/MissRAG
- Faysse, M., Sibille, H., Wu, T., Omrani, B., Viaud, G., Hudelot, C., Colombo, P. (2024). ColPali: Efficient Document Retrieval with Vision Language Models. ICLR 2025. arXiv:2407.01449. Disponível em: https://arxiv.org/abs/2407.01449
- Mao, M., Perez-Cabarcas, M. M., Kallakuri, U., Waytowich, N., Lin, X., Mohsenin, T. (2025). Multi-RAG: A Multimodal Retrieval-Augmented Generation System for Adaptive Video Understanding. arXiv:2505.23990. Disponível em: https://arxiv.org/abs/2505.23990
- Mattos Filho (2025). Artificial Intelligence in the Brazilian Agribusiness Sector. Mattos Filho Advogados. Disponível em: https://www.mattosfilho.com.br/en/unico/artificial-intelligence-brazilian-agribusiness/
- OpenAI (2023). Whisper Large v3 Model Card. OpenAI. Disponível em: https://platform.openai.com/docs/models/whisper
- OpenAI (2024). Hello GPT-4o. OpenAI Blog. Disponível em: https://openai.com/index/hello-gpt-4o/
- OpenAI (2025). Multimodal RAG with CLIP Embeddings and GPT-4 Vision. OpenAI Cookbook. Disponível em: https://developers.openai.com/cookbook/examples/custom_image_embedding_search
- Radford, A., Kim, J. W., Hallacy, C., et al. (2021). Learning Transferable Visual Models From Natural Language Supervision. ICML 2021. arXiv:2103.00020. Disponível em: https://arxiv.org/abs/2103.00020
- Springer (2025). Transforming Brazilian Healthcare with AI: Progress and Future Perspectives. Journal of the Brazilian Clinical Biochemistry Association. Disponível em: https://link.springer.com/article/10.1007/s44250-025-00227-5
- Yue, X., Ni, Y., Zhang, K., et al. (2024). MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI. CVPR 2024. Disponível em: https://mmmu-benchmark.github.io/
Quer construir IA soberana?
Fale com a BaXiJen e descubra como agentes autônomos podem transformar sua operação.
Fale conoscoNewsletter BaXiJen
Conteúdo técnico sobre IA, soberania e produto.
Análises com dados reais, papers acadêmicos e lições de produção. Sem spam, sem buzzword. Um email por semana.