Fine-tuning no Brasil: Custo-Benefício de Treinar vs Usar API
Quanto custa, de verdade, fine-tunar um modelo de linguagem no Brasil? Comparamos API (OpenAI, Google), cloud GPU (Together AI, RunPod) e on-premise com hardware nacional, com números reais em reais. Incluímos análise LGPD, break-even por volume e um framework de decisão para empresas brasileiras escolherem o caminho certo.
Todo mundo fala em "treinar seu próprio modelo" como se fosse cafeteira: aperta um botão e sai. Na prática, a decisão entre fine-tuning e API é uma equação financeira, regulatória e técnica que a maioria das empresas brasileiras ainda não sabe fazer. E o pior: a maioria dos conteúdos sobre custo de fine-tuning ignora que estamos no Brasil, pagando em reais, sujeitos à LGPD, com infraestrutura de GPU muito diferente da de São Francisco.
Este post é o guia que eu gostaria de ter lido antes de decidir entre API e fine-tuning para o BXat. Vamos comparar os três caminhos com números reais, mostrar onde a API vence, onde o fine-tuning compensa, e onde a soberania de dados não é discurso, é exigência legal.
1. Os três caminhos: API, cloud GPU e on-premise
Antes de comparar custos, é preciso entender o que cada opção significa na prática.
API de modelo fechado (OpenAI GPT-4.1, Google Gemini, Anthropic Claude): você envia prompts e recebe respostas. Não treina nada. Usa o modelo como serviço, paga por token. A API de fine-tuning existe (OpenAI oferece fine-tuning de GPT-4.1 e GPT-4.1 mini), mas o modelo resultante continua na infraestrutura do provedor e a inferência pós-fine-tuning custa 1.5x o preço base (aicostcheck, 2026).
Cloud GPU com modelo open-source (Together AI, RunPod, Lambda, Modal): você aluga GPUs por hora, roda fine-tuning com QLoRA ou LoRA em modelos como Qwen3-7B ou Llama 3.1 8B, e serve o modelo resultante onde quiser. O custo é por hora de GPU, não por token. O modelo é seu.
On-premise com hardware próprio: você compra ou aloca GPUs na sua infraestrutura (ou em data centers brasileiros), roda fine-tuning e inferência localmente. Zero dependência de cloud estrangeira. Os dados nunca saem do país. É o caminho da BaXiJen e de qualquer organização sujeita à LGPD com requisitos de residência de dados.
2. Os números: quanto custa fine-tuning em 2026
Vamos ao que interessa. Os preços abaixo refletem cotações de maio de 2026, com câmbio de USD 1 = R$ 5,60.
2.1. Fine-tuning via API (OpenAI)
| Modelo | Treinamento (por 1M tokens) | Inferência input (por 1M) | Inferência output (por 1M) |
|---|---|---|---|
| GPT-4.1 | US$ 25,00 | US$ 3,00 | US$ 12,00 |
| GPT-4.1 mini | US$ 5,00 | US$ 0,80 | US$ 3,20 |
| GPT-4.1 nano | US$ 1,50 | US$ 0,20 | US$ 0,80 |
Fonte: aicostcheck, 2026.
Aqui está o primeiro choque: o fine-tuning de GPT-4.1 custa US$ 25 por milhão de tokens treinados. Um dataset médio de 2.500 exemplos com 500 tokens cada, treinado por 4 epochs (5M tokens totais), sai por US$ 125,00 (R$ 700,00) só em treinamento. E a inferência pós-fine-tuning é 1.5x mais cara que o modelo base.
Para GPT-4.1 nano, o custo cessa. Treinamento a US$ 1,50/M tokens e inferência a US$ 0,20/$0,80. Mas nano é nano: bom para classificação e extração, insuficiente para geração complexa em português.
2.2. Cloud GPU com modelo open-source (Together AI)
| Modelo | Treinamento (por 1M tokens) | Inferência input (por 1M) | Inferência output (por 1M) |
|---|---|---|---|
| Llama 3.1 8B | US$ 0,48 | US$ 0,18 | US$ 0,18 |
| Llama 3.1 70B | US$ 2,90 | US$ 0,88 | US$ 0,88 |
| Mistral 7B | US$ 0,48 | US$ 0,20 | US$ 0,20 |
Fonte: aicostcheck, 2026.
O mesmo dataset de 5M tokens treinados no Llama 3.1 8B via Together AI custa US$ 2,40 (R$ 13,44). Isso não é erro de digitação. É 52x mais barato que o GPT-4.1.
E o paper de Rossi et al. (2026), "Fine-tuning Small Language Models as Efficient Enterprise Foundation Models", demonstrou que SLMs fine-tuned com QLoRA atingem desempenho comparável a GPT-3.5 na maioria das tarefas corporativas, com custo de inferência até 90% menor (Rossi et al., arXiv 2026).
2.3. On-premise: QLoRA em hardware nacional
É aqui que o Brasil precisa fazer as contas diferente. Um estudo detalhado da LÆKA Research mostrou que fine-tunar Qwen3-7B com QLoRA numa A10G spot custa US$ 2,50 total (3 horas a US$ 0,60-0,80/hora) (LÆKA, 2026). No Brasil, com RTX 3090 (24GB VRAM) adquirida por ~R$ 5.500, o custo marginal por fine-tuning é essencialmente zero após a compra do hardware.
A matemática é simples:
- RTX 3090 (24GB): fine-tuning QLoRA de modelos até 7B parâmetros. Consumo: ~300W. Custo de energia por hora de treino: ~R$ 0,25 (tarifa residencial RJ).
- 2x RTX 3060 12GB (configuração da BaXiJen): fine-tuning até ~14B com QLoRA. Mesmo consumo proporcional.
- A100 80GB (aluguel em cloud): US$ 2,00-3,50/hora. Fine-tuning de modelos até 70B com LoRA.
Um fine-tuning completo de Qwen3-7B com QLoRA em RTX 3090, 3 epochs, 2.000 exemplos, leva 2-3 horas. Custo de energia: menos de R$ 1,00. Custo de hardware já amortizado: R$ 0,00 marginal.
O artigo da NeuralWired sobre SLMs corporativos aponta que a AT&T migrou suporte automatizado para modelos Mistral e Phi fine-tuned em 2026 e reportou redução de 90% nos custos mensais de API com 70% de melhoria no tempo de resposta (NeuralWired, 2026). Esses números não são teóricos. São de produção.
3. A dimensão LGPD que ninguém coloca na planilha
Aqui é onde a decisão deixa de ser só financeira e vira jurídica. A LGPD (Lei 13.709/2018) exige, no Art. 33, que a transferência internacional de dados pessoais só ocorra quando o país de destino garanta nível adequado de proteção, ou quando houver consentimento específico, cláusulas contratuais ou cooperação internacional.
Na prática, isso significa: se você fine-tuna um modelo na OpenAI, seus dados de treinamento viajam para os EUA. Se você usa Together AI, idem. Se você usa inferência via API, os dados dos seus usuários saem do Brasil a cada request. Um relatório da Proofnox sobre soberania de dados em 2026 aponta que mais de 100 países já possuem leis de localização ou soberania de dados, e a LGPD é uma das mais restritivas (Proofnox, 2026).
Para empresas públicas, órgãos governamentais e instituições financeiras brasileiras, a residência de dados não é opcional. É requisito. E é aqui que o on-premise deixa de ser ideologia e vira compliance.
A BaXiJen construiu o BXat exatamente por isso: modelos open-source, fine-tuning local, inferência local, dados nunca saem do servidor do cliente. Não é discurso. É LGPD.
4. Quando cada caminho compensa: framework de decisão
Não existe resposta universal. Existe o caminho certo para o seu caso de uso. O framework abaixo usa três variáveis: volume diário de requests, sensibilidade dos dados e necessidade de customização.
4.1. API vence quando
- Volume baixo (< 1.000 requests/dia): o custo fixo de infraestrutura não se amortiza. Um prompt bem construído com few-shot examples resolve.
- Requisitos mudam frequentemente: se o formato de saída, o domínio ou o tom mudam toda semana, iterar no prompt é mais rápido que re-treinar.
- Tarefa genérica: resumo, tradução, Q&A geral. Modelos como GPT-4.1 mini ou Gemini 2.0 Flash já fazem bem sem fine-tuning.
O ponto de crossover, segundo análise do aicostcheck, fica entre 5.000 e 10.000 requests/dia. Abaixo disso, o custo do fine-tuning (dataset + treinamento + infra) raramente se justifica frente a um prompt bem feito.
4.2. Cloud GPU vence quando
- Volume médio-alto (10.000+ requests/dia): a diferença de custo por token entre Together AI e OpenAI se acumula. A inferência de Llama 3.1 8B fine-tuned a US$ 0,18/1M tokens é 17x mais barata que GPT-4.1 fine-tuned a US$ 3,00/1M.
- Customização de domínio é necessária: jurisprudência brasileira, terminologia médica, normas regulatórias específicas. O fine-tuning internaliza esse conhecimento.
- Dados podem sair do Brasil para treinamento (mas não para inferência): treine na cloud, sirva on-premise. É o modelo híbrido.
4.3. On-premise vence quando
- Dados sensíveis ou regulados (LGPD): saúde, finanças, governo. Treinamento e inferência no Brasil, sem transferência.
- Volume alto (50.000+ requests/dia): custo marginal de inferência próximo de zero. A RTX 3090 que custa R$ 5.500 se paga em 2-3 meses se substituir uma API de US$ 50/dia.
- Latência é crítica: inferência local em GPU dedicada bate 180+ tokens/segundo no Llama 3.1 8B. Via API, você compete por rate limits e latência de rede.
- Soberania é requisito, não preferência: empresas públicas, estatais, órgãos governamentais. O dado não pode sair do país. Ponto.
5. Custo total de propriedade: simulação realista
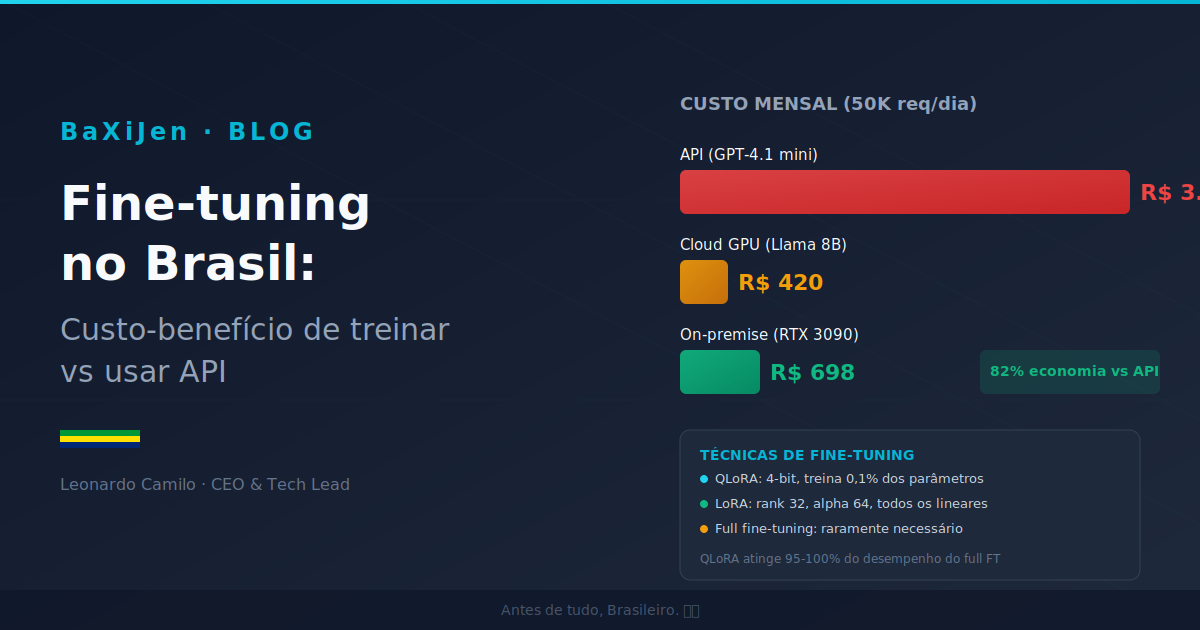
Vamos comparar os três caminhos para um cenário típico brasileiro: uma empresa processando 50.000 requests/dia, com contexto de 500 tokens input e 300 tokens output, modelo fine-tuned para classificação e extração em português.
| Item | OpenAI (GPT-4.1 mini fine-tuned) | Together AI (Llama 3.1 8B fine-tuned) | On-premise (RTX 3090) |
|---|---|---|---|
| Treinamento (5M tokens, 4 epochs) | R$ 700 (US$ 125) | R$ 14 (US$ 2,40) | R$ 1 (energia) |
| Inferência/dia (50K requests) | R$ 130 (US$ 23,20) | R$ 14 (US$ 2,52) | R$ 8 (energia) |
| Inferência/mês | R$ 3.900 | R$ 420 | R$ 240 |
| Hardware (amortização 12 meses) | R$ 0 | R$ 0 | R$ 458 |
| Custo mensal total | R$ 3.900 | R$ 420 | R$ 698 |
| Break-even vs API | : : | 1 mês | 2 semanas |
Notas: OpenAI cobra 1.5x na inferência de fine-tuned. Together AI cobra preço base. On-premise considera 1x RTX 3090 (R$ 5.500/12 meses) + energia. Todos os valores em reais, maio 2026.
O resultado é claro: para volume alto, on-premise se paga em dias. Para volume médio, cloud GPU com modelo open-source é a melhor relação custo-benefício. Para volume baixo, API ainda faz sentido.
6. Lições da BaXiJen: o que aprendemos fine-tunando para o setor público
Na prática, a BaXiJen fine-tuna modelos como o Qwen3 e Llama 3.1 em hardware próprio (2x RTX 3060 12GB e RTX 3090) para o BXat, nosso assistente de IA para gestão pública. As lições que aprendemos:
Dataset é 80% do resultado. Nosso primeiro fine-tuning com 500 exemplos foi medíocre. Com 2.000 exemplos curados, a qualidade saltou. Não adianta ter GPU potente se os dados são ruins.
QLoRA é suficiente para 90% dos casos. Não precisamos de full fine-tuning. QLoRA com rank 32, alpha 64, todos os módulos lineares, 3 epochs. Receita testada e comprovada. O paper do Hu et al. (2021) que introduziu LoRA mostrou que treinar 0,1% dos parâmetros atinge 95-100% do desempenho do full fine-tuning (Hu et al., 2021). QLoRA (Dettmers et al., 2023) estendeu isso para quantização 4-bit sem perda mensurável de qualidade (Dettmers et al., 2023).
O custo real é tempo de engenharia, não GPU. Um fine-tuning de Qwen3-7B custa menos de R$ 1,00 em energia. Mas curar 2.000 exemplos de qualidade leva 20-40 horas de engenheiro. A R$ 150/hora, são R$ 3.000-6.000. O GPU barato; o humano, não.
On-premise não é apenas barato, é seguro. Para o setor público brasileiro, não é questão de preferência. Os dados do cidadão não podem cruzar fronteiras sem base legal. Fine-tuning local é o caminho.
7. Checklist: como decidir na segunda-feira
- Liste seus requisitos de dados. Se há LGPD envolvida, corte API e cloud estrangeira da lista.
- Calcule seu volume diário. Abaixo de 5.000 requests/dia, prompt engineering pode ser suficiente.
- Avalie a customização necessária. Se o modelo precisa "falar" o jargão do seu domínio (jurídico, médico, regulatório), fine-tuning entrega resultado que prompt não alcança.
- Compare TCO em 12 meses. Inclua dataset curation, treinamento, inferência, hardware e tempo de engenharia.
- Comece com QLoRA em modelo pequeno. Teste com 500-1.000 exemplos. Se funciona, expanda. Se não funciona, o problema é o dataset, não o modelo.
Referências
-
aicostcheck. (2026). AI Fine-Tuning Costs 2026: Training, Inference, and ROI Compared. https://aicostcheck.com/blog/ai-fine-tuning-costs-2026
-
Dettmers, T., Pagnoni, A., Zettlemoyer, L., & Holtzman, A. (2023). QLoRA: Efficient Finetuning of Quantized LLMs. arXiv:2305.14314. https://arxiv.org/abs/2305.14314
-
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685. https://arxiv.org/abs/2106.09685
-
LÆKA Research. (2026). How to Fine-Tune Qwen3 on a $2.50 Budget. https://laeka.si/research/how-to-fine-tune-qwen3-on-a-dollar250-budget/
-
NeuralWired. (2026). Small Language Models: The Enterprise AI Buyer's Guide. https://neuralwired.com/2026/02/22/small-language-models-enterprise-guide/
-
Proofnox. (2026). Data Residency, Sovereignty & Compliance 2026. https://www.proofnox.com/en/blog/data-residency-sovereignty-compliance-2026
-
Rossi, A., et al. (2026). Fine-tuning Small Language Models as Efficient Enterprise Foundation Models. arXiv:2512.15943. https://arxiv.org/abs/2512.15943
-
Scopic Software. (2026). The Real Cost of Fine-Tuning LLMs: What You Need to Know. https://scopicsoftware.com/blog/cost-of-fine-tuning-llms/
Quer construir IA soberana?
Fale com a BaXiJen e descubra como agentes autônomos podem transformar sua operação.
Fale conoscoNewsletter BaXiJen
Conteúdo técnico sobre IA, soberania e produto.
Análises com dados reais, papers acadêmicos e lições de produção. Sem spam, sem buzzword. Um email por semana.