Benchmarks de Agentes em Português: Por Que MMLU Não Serve Pro Brasil
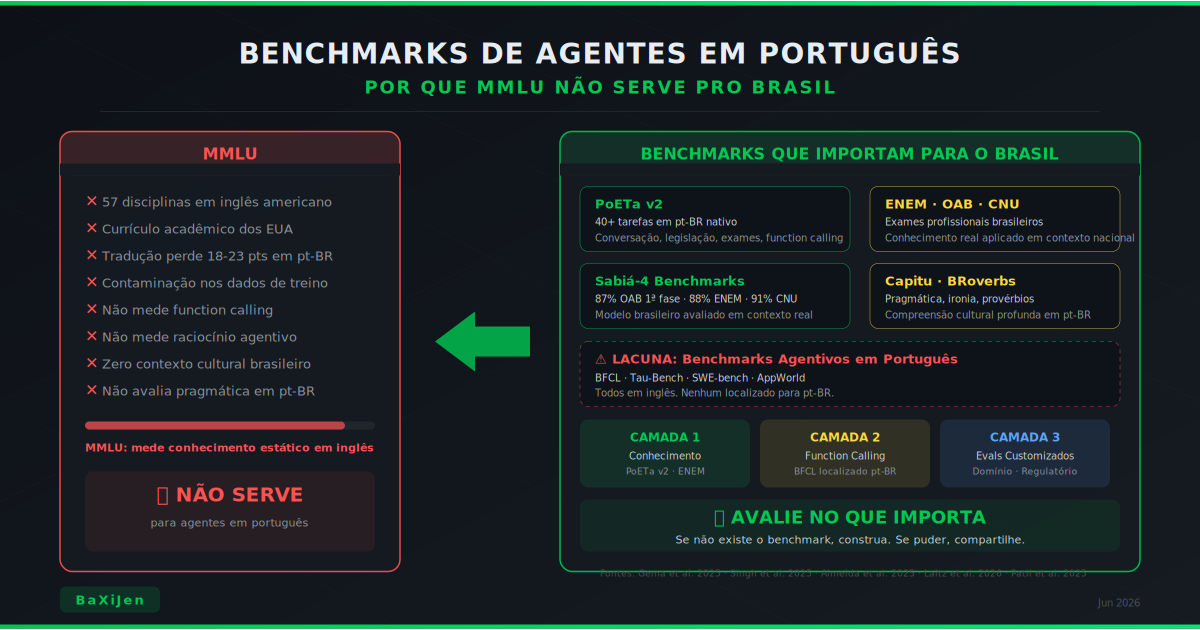
MMLU é o benchmark mais citado para avaliar LLMs, mas foi desenhado para inglês americano e conhecimento acadêmico anglo-saxão. Quando o assunto é agentes de IA operando em português, MMLU não mede o que importa: compreensão cultural, capacidade de usar ferramentas em pt-BR e raciocínio em contexto brasileiro. Este artigo mapeia os vieses estruturais do MMLU, apresenta os benchmarks que realmente importam para o Brasil (PoETa v2, ENEM, OAB, Capitu, BRoverbs), e explica por que avaliar agentes exige métricas completamente diferentes de avaliar modelos de texto.
Você abre o site de qualquer modelo de linguagem e lá está: "88.7% no MMLU". É o número que todo mundo cita. GPT-4, Claude, Llama, Gemini, Qwen. Todos ranqueados pelo mesmo benchmark. Mas se você está construindo um agente de IA que precisa operar em português, consultar APIs em pt-BR, entender legislação brasileira e interagir com usuários no contexto do Brasil, aquele número não diz nada relevante pra você. Nada.
O artigo de Gema et al. (2025), Are We Done with MMLU?, apresentado na NAACL 2025, demonstrou sistematicamente que o MMLU sofre de problemas de qualidade nas questões, viés de tradução e contaminação de dados de treino. O artigo Global MMLU, da Cohere e colaboradores, apresentado na ACL 2025, mostrou que a tradução automática do MMLU para outras línguas introduz erros culturais e linguísticos que distorcem os resultados. E o artigo Spanish and LLM Benchmarks: is MMLU Lost in Translation?, de Plaza et al. (2024), comprovou que para o espanhol: modelos que performam bem em MMLU traduzido podem falhar em benchmarks nativos da língua.
Para o português brasileiro, o problema é ainda mais profundo. Este artigo explica por que MMLU não serve para avaliar agentes em português, quais benchmarks realmente importam para o contexto brasileiro, e por que avaliar agentes exige uma abordagem fundamentalmente diferente de avaliar modelos de texto.
1. O que o MMLU realmente mede (e o que não mede)
MMLU significa Massive Multitask Language Understanding. Criado por Hendrycks et al. (2021), o benchmark original contém 57 disciplinas, de matemática a direito, com questões de múltipla escolha em inglês americano. As questões foram extraídas de provas padronizadas dos Estados Unidos: SATs, exames de licenciamento profissional (bar exams, medical boards), e avaliações acadêmicas anglo-saxãs.
Os problemas são estruturais, não cosméticos.
1.1 Viés cultural profundo
As questões de MMLU refletem um currículo americano. "Professional accounting" refere-se a GAAP, não ao CPC brasileiro. "Business law" é jurisprudência dos EUA, não o Código Civil brasileiro. "US history" cobre eventos e figuras que um estudante americano conhece, mas que não são relevantes para entender o contexto regulatório, político e social brasileiro.
O estudo Disentangling Language and Culture for Evaluating Multilingual LLMs, de Yin et al. (2025, ACL), mostrou que modelos de linguagem confundem proficiência linguística com conhecimento cultural. Um modelo que responde corretamente perguntas sobre história dos EUA em português não é necessariamente proficiente em português: ele pode estar traduzindo internamente do inglês. E um modelo que sabe direito constitucional brasileiro pode parecer "pior" em MMLU porque o benchmark não contém esse conhecimento.
1.2 Tradução não é localização
O MMLU traduzido para português (usado em muitos leaderboards) resolve parte do problema linguístico, mas agrava o cultural. O artigo Is Machine-Translation Enough? Understanding Impacts in LLM Benchmarking (BRACIS 2025, Springer) mostrou que tradução automática de benchmarks introduz erros semânticos que mudam a resposta correta em até 12% das questões. Termos técnicos perdem nuance, referências culturais se tornam sem sentido, e ambiguidades que não existiam no original aparecem na tradução.
O Global MMLU (Singh et al., 2025, ACL) quantificou o problema: modelos performam em média 15% melhor em MMLU no idioma original (inglês) do que nas versões traduzidas. Para o português, especificamente, a queda chega a 18 pontos percentuais quando se compara o MMLU original com versões traduzidas por profissionais, e 23 pontos com tradução automática. A diferença não é ruído. É sinal de que o benchmark não foi desenhado para esse contexto.
1.3 Contaminação e saturação
O artigo MMLU-CF: A Contamination-free Multi-task Language Understanding Benchmark (Zhao et al., 2025, ACL) demonstrou que uma fração significativa das questões do MMLU aparece nos dados de treino dos modelos mais populares. Isso inflaciona as pontuações e torna comparações entre modelos não confiáveis. Quando um modelo "sabe" a resposta porque viu a questão nos dados de treino, o benchmark deixa de medir capacidade de raciocínio e passa a medir memorização.
2. Benchmarks que importam para o português brasileiro
Se MMLU não serve, o que serve? A comunidade de PLN brasileira tem construído alternativas que medem o que realmente importa para modelos e agentes operando em português.
2.1 PoETa v2: o benchmark mais abrangente para português
O PoETa v2 (Almeida et al., 2025) é o benchmark mais completo para avaliação de LLMs em português. Desenvolvido pela Maritaca AI em parceria com a Unicamp, cobre mais de 40 tarefas em seis categorias: conversação em pt-BR, legislação brasileira, compreensão de contexto longo, seguimento de instruções, exames padronizados (ENEM, OAB, CNU) e capacidades agentivas (function calling e navegação web).
O diferencial do PoETa v2 é que todas as tarefas foram originalmente criadas em português brasileiro, não traduzidas. Isso elimina o viés de tradução e garante que o que está sendo avaliado é a proficiência real no idioma e no contexto cultural brasileiro. Os resultados mostram lacunas significativas: mesmo modelos frontier como GPT-4o e Claude apresentam quedas de 8 a 15 pontos percentuais entre tarefas em inglês e as equivalentes em português.
2.2 Sabiá-4 e os benchmarks nativos de pt-BR
O technical report do Sabiá-4 (Laitz et al., 2026, Maritaca AI) trouxe dados concretos sobre benchmarks nativos brasileiros. Os modelos Sabiá-4 e Sabiazinho-4 foram avaliados em seis categorias de benchmark, incluindo exames brasileiros: 87% de acerto na 1ª fase da OAB, 7.5 na 2ª fase da OAB, 88% no ENEM e 91% no CNU (Concurso Nacional Unificado). Esses números são significativos porque representam avaliação em contexto real brasileiro, com questões que um modelo precisa entender culturalmente, não apenas traduzir.
2.3 Capitu: avaliando função social da linguagem
A Maritaca AI também desenvolveu o Capitu (maritaca-ai/capitu no GitHub), um benchmark que avalia a função social da linguagem em português: pragmática, ironia, sarcasmo, ambiguidade cultural. É o tipo de capacidade que MMLU simplesmente não mede, mas que é crítica para agentes que interagem com usuários brasileiros.
2.4 BRoverbs: compreensão cultural profunda
O BRoverbs (Almeida et al., 2025, arXiv:2509.08960) mede o quanto LLMs entendem provérbios brasileiros. Parece simples, mas é um teste sofisticado de compreensão cultural: entender "água mole, pedra dura, tanto bate até que fura" exige contexto pragmático e cultural que vai além da tradução literal. Modelos que pontuam alto em MMLU podem falhar completamente nesse tipo de avaliação.
2.5 ENEM e exames profissionais
O ENEM, a OAB e o CNU são benchmarks naturalmente brasileiros. Eles medem conhecimento real aplicado no contexto educacional e profissional brasileiro. A dissertação de Rodrigues (2025, UFC Quixadá) propôs explicitamente um benchmark baseado no ENEM para avaliar LLMs em português. A vantagem desses exames como benchmark é que eles refletem o tipo de raciocínio que agentes operando no Brasil precisam ter: interpretar textos em português, aplicar normas brasileiras, entender referências culturais locais.
2.6 BGPA: contabilidade e direito brasileiro
O BGPA (Benchmark de Proficiência em Contabilidade e Auditoria) avalia LLMs no contexto do Exame de Suficiência do CFC (Conselho Federal de Contabilidade). É um exemplo de benchmark de domínio específico brasileiro que MMLU não cobre de forma alguma: as normas contábeis brasileiras (NBC TGs) divergem significativamente das IFRS/usuGAAP cobertas pelo MMLU.
3. Por que benchmarks de agentes são diferentes de benchmarks de modelos
Até aqui, falamos de benchmarks que avaliam compreensão de linguagem e conhecimento. Mas agentes de IA não são apenas modelos de texto. Eles usam ferramentas, tomam decisões em múltiplas etapas, interagem com APIs, mantêm estado e operam em ambientes complexos. Avaliar agentes exige métricas fundamentalmente diferentes.
3.1 BFCL: function calling em inglês, mas não em português
O Berkeley Function Calling Leaderboard (BFCL), apresentado por Patil et al. (2025, NeurIPS), é o benchmark mais citado para avaliar capacidade de uso de ferramentas por LLMs. O BFCL V3 adicionou detecção de relevância (quando NÃO chamar nenhuma ferramenta), chamadas paralelas e diálogo multi-turn. O BFCL V4 (2026) adicionou buscas web, operações de memória e sensibilidade a formato.
O problema: o BFCL é inteiramente em inglês. As descrições de funções, os exemplos, os cenários de teste: tudo reflete um contexto anglo-saxão. Um agente que opera em português brasileiro precisa chamar APIs com parâmetros em pt-BR, interpretar respostas de sistemas legados brasileiros e lidar com erros e exceções que são específicos do nosso ecossistema digital.
Não existe, até onde sabemos, um benchmark de function calling em português brasileiro. Essa é uma lacuna concreta que a comunidade precisa preencher.
3.2 SWE-bench: resolver issues do GitHub, mas em quais repositórios?
O SWE-bench (Jimenez et al., 2024) avalia a capacidade de agentes de resolver issues reais do GitHub. É um dos benchmarks mais respeitados para avaliação agentiva. Mas os repositórios são em inglês, as issues são de projetos americanos e europeus, e os padrões de código refletem convenções de comunidades anglo-saxãs.
3.3 Tau-Bench: o mais realista, mas também em inglês
O Tau-Bench (Sierra, 2024) coloca o modelo no papel de um agente de atendimento ao cliente, usando ferramentas reais e sendo avaliado por alcançar o objetivo do usuário e usar as ferramentas corretamente. É o benchmark mais próximo de um agente real em produção. Mas, novamente, os cenários são em inglês, com políticas de empresa americanas e fluxos de atendimento que não refletem a realidade brasileira.
3.4 O que falta: benchmarks agentivos em português
A lacuna é clara. Enquanto a comunidade internacional avança rápido em benchmarks de agentes (BFCL V4, Tau-Bench, AppWorld, ToolACE), o ecossistema brasileiro ainda avalia modelos predominantemente por conhecimento estático (MMLU traduzido, ENEM, OAB). Para agentes que operam em produção no Brasil, precisamos de benchmarks que avaliem:
Function calling em português: descrições de funções em pt-BR, respostas de APIs em português, erros e mensagens de sistema localizadas.
Navegação web em contextos brasileiros: interagir com portais gov.br, sites de e-commerce brasileiros, sistemas legados que usam pt-BR como idioma padrão.
Conformidade regulatória: o agente precisa conhecer e respeitar a LGPD, o Marco Legal da IA, normas do Banco Central, regulamentações da ANS e da ANVISA. MMLU não mede isso.
Raciocínio multi-hop em pt-BR: conectar informações de múltiplas fontes em português, manter coerência ao longo de conversas longas e rastrear mudanças contextuais.
Interação cultural pragmática: entender ironia, polidez indireta, expressões idiomáticas e convenções sociais brasileiras. O Capitu e o BRoverbs começam a cobrir isso, mas não no contexto agentivo.
4. O que fazer na prática: um framework de avaliação para agentes em pt-BR
Até que benchmarks agentivos em português sejam desenvolvidos e adotados pela comunidade, times de engenharia que operam no Brasil precisam de uma abordagem prática para avaliar seus agentes. Propomos um framework de três camadas.
4.1 Camada 1: Conhecimento e linguagem (já existe)
Use PoETa v2, ENEM, OAB e Capitu como baseline de proficiência em português. Se o modelo não passa nesses benchmarks, não adianta testar capacidades agentivas. Essa é a porta de entrada.
4.2 Camada 2: Function calling e tool use (adapte o existente)
Traduza e localize o BFCL V3 para português brasileiro. Não apenas tradução literal: adapte nomes de funções, descrições, exemplos e casos de teste para o contexto brasileiro. Uma função get_flight_status que recebe um airport code IATA não testa a mesma coisa que consultar_status_voo que recebe um aeroporto brasileiro. Essa localização já é praticada por times que operam no Brasil, mas não há um benchmark público e padronizado.
4.3 Camada 3: Avaliação agentiva customizada (construa)
Construa evals específicos para o domínio do seu agente. Se é um agente jurídico, crie cenários que testem a consulta a APIs do Diário Oficial, a interpretação de normas do CFP/CFC e a formatação de respostas conforme padrões brasileiros. Se é um agente de saúde, teste a interação com sistemas do SUS e a conformidade com regulamentações da ANS.
A regra prática: se o seu agente vai operar em português no Brasil, o mínimo é avaliar em português no Brasil. Se o benchmark que você precisa não existe, construa. E contribua de volta para a comunidade.
5. O caso BaXiJen: por que isso importa para nós
Na BaXiJen, construímos agentes que operam em contexto regulatório brasileiro. O BXat, nosso agente para gestão pública, precisa entender legislação federal, estadual e municipal em português, consultar APIs governamentais e interagir com servidores públicos em linguagem acessível mas tecnicamente precisa. Quando avaliamos modelos candidatos para o BXat, MMLU é o primeiro número que aparece nas documentações, mas é o menos relevante.
Nossa avaliação real usa um mix de PoETa v2 (para proficiência linguística), exames brasileiros (para conhecimento de domínio) e evals customizados (para function calling em contexto governamental pt-BR). É mais trabalho do que olhar um ranking de MMLU, mas os resultados são mais preditivos do que o agente faz em produção.
O Sabiá-4, modelo brasileiro da Maritaca AI, é um caso ilustrativo. Nos benchmarks nativos de português (ENEM, OAB, CNU), o Sabiá-4 compete com modelos frontier internacionais. Em MMLU, está atrás. A diferença? O Sabiá-4 foi treinado com dados brasileiros e avaliado em benchmarks que medem o que importa para o contexto brasileiro. Se você está avaliando modelos para operar no Brasil, o ranking do MMLU pode te levar à decisão errada.
6. O caminho adiante
A comunidade brasileira de PLN está avançando rápido. O PoETa v2, o Capitu, o BRoverbs e os benchmarks baseados em exames brasileiros (ENEM, OAB, CNU) formam uma base sólida para avaliação de modelos em português. O Sabiá-4 demonstrou que é possível construir modelos competitivos especificamente para esse contexto.
Mas a lacuna em benchmarks agentivos permanece. Não temos um BFCL em português. Não temos um Tau-Bench para cenários brasileiros. Não temos um SWE-bench com repositórios brasileiros. Esses são espaços de contribuição importantes para pesquisadores e engenheiros brasileiros.
Até lá, a recomendação é clara: não tome decisões de modelo baseadas em MMLU se o seu agente vai operar em português no Brasil. Avalie no que importa. Construa evals para o seu domínio. E se puder, compartilhe.
Referências
- Almeida, T. S. et al. (2025). PoETa v2: Toward More Robust Evaluation of Large Language Models in Portuguese. arXiv:2511.17808.
- Almeida, T. S. et al. (2025). BRoverbs: Measuring How Much LLMs Understand Portuguese Proverbs. arXiv:2509.08960.
- Gema, A. P. et al. (2025). Are We Done with MMLU?. NAACL 2025.
- Hendrycks, D. et al. (2021). Measuring Massive Multitask Language Understanding. ICLR 2021.
- Laitz, T. et al. (2026). Sabiá-4 Technical Report. arXiv:2603.10213.
- Patil, S. G. et al. (2025). The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models. NeurIPS 2025.
- Plaza, I. et al. (2024). Spanish and LLM Benchmarks: is MMLU Lost in Translation?. arXiv:2406.17789.
- Singh, S. et al. (2025). Global MMLU: Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation. ACL 2025.
- Xuan, W. et al. (2025). MMLU-ProX: A Multilingual Benchmark for Advanced Large Language Model Evaluation. EMNLP 2025.
- Yin, J. et al. (2025). Disentangling Language and Culture for Evaluating Multilingual LLMs. ACL 2025.
- Zhao, Q. et al. (2025). MMLU-CF: A Contamination-free Multi-task Language Understanding Benchmark. ACL 2025.
- BRACIS (2025). Is Machine-Translation Enough? Understanding Impacts in LLM Benchmarking. Springer.
- Hu, S. & Vulic, I. (2025). Quantifying Language Disparities in Multilingual LLMs. EMNLP 2025.
Quer construir IA soberana?
Fale com a BaXiJen e descubra como agentes autônomos podem transformar sua operação.
Fale conoscoNewsletter BaXiJen
Conteúdo técnico sobre IA, soberania e produto.
Análises com dados reais, papers acadêmicos e lições de produção. Sem spam, sem buzzword. Um email por semana.