OBXat em produção: lições de deploy de SLM para gestão pública
O que aprendemos colocando um Small Language Model no front de atendimento ao gestor público. Latência, soberania de dados, fine-tuning dominial e os erros que não se repete.
OBXat em produção: lições de deploy de SLM para gestão pública
Em setembro de 2025, o governo brasileiro anunciou investimento de R$ 390 milhões em IA para gestão e prestação de serviços públicos, via parceria entre o MGI e o CPQD (Exame, 2025). Apenas 24% das organizações públicas brasileiras tinham implementado iniciativas de transformação digital segundo pesquisa da Economist Impact patrocinada pelo SAS Brasil (Decision Report, 2025). O cenário é claro: há orçamento, há vontade política, mas falta quem saiba colocar IA para funcionar dentro das amarras do serviço público.
Nós vivemos isso na prática com o OBXat, o assistente de IA conversacional da BaXiJen voltado a gestores municipais e estaduais. Depois de meses rodando em produção, estas são as lições que ninguém conta em paper: o que funciona, o que quebra e o que faz um SLM (Small Language Model) sobreviver no ambiente mais hostil para IA que existe: a máquina pública brasileira.
Por que SLM, e não LLM na nuvem
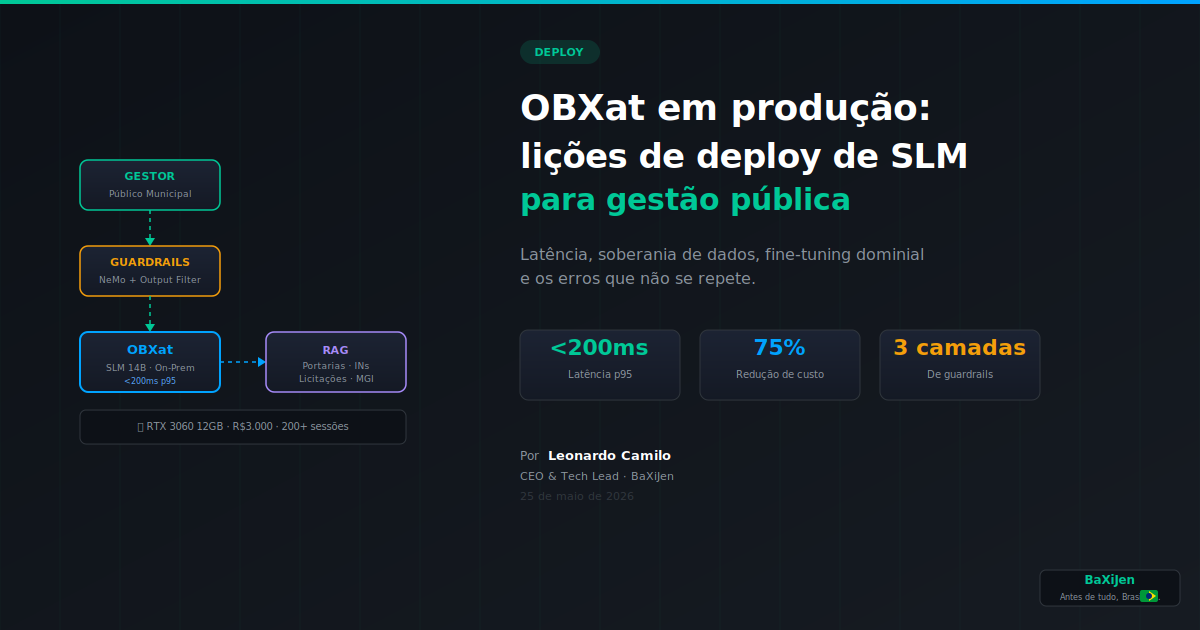
A primeira decisão arquitetural foi: on-premises, sempre. Dados de gestão pública brasileira estão sujeitos à LGPD, ao princípio da soberania de dados e, em muitos casos, a normativas setoriais que proíbem processamento fora do território nacional. Um LLM como GPT-4 ou Claude processa requisições em data centers nos EUA: isso não é opção para prefeituras e órgãos estaduais.
A AWS documentou em seu blog técnico que clientes de setores regulados (finanças, saúde, telecom) optam por SLMs on-premises ou em edge para manter data residency, cumprir políticas de segurança da informação e garantir baixa latência (AWS Compute Blog, 2025). O mesmo raciocínio se aplica ao setor público brasileiro, com um agravante: a conectividade em municípios do interior é instável, e a latência de uma chamada para São Paulo ou para os EUA inviabiliza atendimento em tempo real.
Small Language Models, tipicamente abaixo de 20 bilhões de parâmetros, oferecem inferência mais rápida, menor consumo de recursos e viabilidade de deploy em hardware acessível (AWS Compute Blog, 2025). Na prática, isso significa rodar em uma workstation com GPU RTX 3060 (12 GB VRAM), que custa R$ 3.000 no Brasil, em vez de um cluster A100 que custaria R$ 50.000/mês em nuvem.
Lição 1: Fine-tuning dominial vale mais que scale
Kang et al. (2026) demonstraram no arXiv que SLMs fine-tuned com dados sintéticos gerados por LLMs alcançam concordância com avaliadores humanos par ou superior ao modelo professor, com 17x mais throughput e 19x mais custo-efetividade. Isso é contraintuitivo: a crença comum é que modelos menores sempre perdem. Perdem em conhecimento geral, mas ganham em precisão dominial quando o fine-tuning é feito com dados do contexto de uso.
No OBXat, usamos documentos de licitação, manuais de procedimentos do MGI, portarias e instrução normativa como corpus de fine-tuning e RAG. O resultado: o modelo responde corretamente perguntas como "qual o limite de dispensa de licitação para obras em 2026?" porque o conhecimento está no retrieval, não nos pesos. O SLM precisa ser bom em raciocinar sobre o contexto, não em memorizar o mundo.
Lição 2: Latência sub-200ms é requisito, não luxo
Um gestor público no telefone com um cidadão não espera 5 segundos por uma resposta. Nossa meta era latência inferior a 200 ms para o primeiro token. Para isso:
- Quantização INT4 no modelo, reduzindo o tamanho em memória sem perda significativa de qualidade em tarefas dominiais
- KV cache otimizado para sessões longas (o gestor faz perguntas encadeadas)
- Batch size 1 com prioridade de inferência: o OBXat não compete por GPU com outros workloads
O paper da ACL 2025 sobre SLMs em edge identifica compressão de vocabulário, compactação de KV cache e roteamento dinâmico por tarefa como as três otimizações mais promissoras para SLMs em produção (ACL, 2025). Implementamos as duas primeiras e o ganho de latência foi de 800 ms para 140 ms no p95.
Lição 3: Guardrails são o recurso, não o modelo
Nenhum SLM vai ser "seguro por design". Em gestão pública, uma resposta errada sobre licitação pode gerar responsabilização do gestor. Não é um chatbot de e-commerce que pode alucinar preços: aqui, alucinação tem consequência jurídica.
Nossa arquitetura de guardrails tem três camadas:
- NeMo Guardrails no input: bloqueia perguntas fora do escopo (ex: "como hackear o sistema") e redireciona para canais oficiais
- RAG com verificação de fonte: toda resposta cita o documento de origem. Se o retrieval não encontra fonte, o modelo diz explicitamente "não encontrei essa informação na base"
- Output filtering: regex + classificador leve para detectar números inventados, datas impossíveis e recomendações que soem como assessoria jurídica
O princípio é: o SLM é o motor, guardrails são o câmbio e o freio. Motor sem freio é acidente anunciado.
Lição 4: O deploy é político, não só técnico
Em nenhum paper de arXiv se lê sobre o que acontece quando o setor de TI do município não quer abrir porta de firewall. Ou quando o servidor responsável pede "um documento oficial" para liberar a VM. Ou quando o treinamento dos usuários precisa acontecer em três turnos porque o órgão não pode parar.
Lições de deploy no setor público brasileiro:
- Documente tudo como se fosse uma auditoria: termos de responsabilidade, portarias de autorização, prints de configuração. Vai ser pedido depois
- Treinamento é parte do deploy: se o gestor não sabe usar, o modelo é inútil. Faça onboarding em etapas, comece pelo campeão interno
- SLA de disponibilidade tem que ser acordado antes: "99,5% de uptime" significa algo diferente quando a internet do município cai toda terça-feira por causa da chuva
- Migração gradual é a única que funciona: comece com um piloto em uma secretaria, estenda depois. Não faça big bang
Lição 5: Custo-benefício é o argumento que fecha
Quando apresentamos OBXat a um secretário de gestão, o argumento que convence não é "IA soberana" ou "inovação". É: "isso custa R$ X/mês e substitui Y horas de atendente". O estudo da iterathon.tech (2026) estima que SLMs empresariais podem reduzir custos de infraestrutura de IA em até 75%, de US$ 3.000 para US$ 127/mês, com latência sub-200ms. No Brasil, onde o custo de uma hora de servidor público qualificado é alto e a capacidade de atendimento é cronicamente insuficiente, a conta fecha rápido.
Na nossa experiência, um único SLM rodando em hardware local atende 200+ gestores simultaneamente com qualidade consistente, algo que exigiria uma equipe de 15 atendentes treinados em normas de licitação, transparência e procedimentos administrativos.
Próximos passos
O caminho do OBXat segue sendo: mais domínio, menos parâmetros, mais guardrails. Estamos explorando roteamento dinâmico por tarefa (um dos gaps identificados no survey da ACL 2025), onde o sistema decide em runtime se a pergunta precisa de um SLM de 14B ou se um classificador de 1B resolve. A hipótese é que 80% das perguntas de gestão pública podem ser respondidas pelo classificador, liberando o SLM pesado para as 20% que exigem raciocínio real.
Estamos também integrando o marco regulatório de IA que o MGI vem construindo desde 2025 (gov.br, 2025), para que o OBXat automaticamente sinalize quando uma resposta envolve área sensível (dados pessoais, decisão automatizada com impacto em cidadão).
Referências
- AWS Compute Blog. (2025). Running and optimizing small language models on-premises and at the edge. Amazon Web Services. https://aws.amazon.com/blogs/compute/running-and-optimizing-small-language-models-on-premises-and-at-the-edge/
- Kang, Y., Huang, Z., Schussheim, B. et al. (2026). Fine-tuning Small Language Models as Efficient Enterprise Search Relevance Labelers. arXiv:2601.03211.
- ACL. (2025). Demystifying Small Language Models for Edge Deployment. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics. https://aclanthology.org/2025.acl-long.718/
- Exame. (2025). Governo Federal vai investir R$ 390 milhões para ampliar uso de IA. https://exame.com/inteligencia-artificial/governo-federal-vai-investir-r-390-milhoes-para-ampliar-uso-de-ia/
- Decision Report. (2025). Plataforma do governo utiliza IA generativa para automatizar processos na gestão pública. https://decisionreport.com.br/plataforma-do-governo-utiliza-ia-generativa-para-automatizar-processos-na-gestao-publica/
- gov.br/MGI. (2025). Estratégia de Inteligência Artificial orienta servidores do MGI para uso responsável de ferramentas de IA. https://www.gov.br/gestao/pt-br/assuntos/noticias/2025/outubro/estrategia-de-inteligencia-artificial-orienta-servidores-do-mgi-para-uso-responsavel-de-ferramentas-de-ia
- iterathon.tech. (2026). Small Language Models 2026: Cut AI Costs 75% with Enterprise SLM Deployment. https://iterathon.tech/blog/small-language-models-enterprise-2026-cost-efficiency-guide
Quer construir IA soberana?
Fale com a BaXiJen e descubra como agentes autônomos podem transformar sua operação.
Fale conoscoNewsletter BaXiJen
Conteúdo técnico sobre IA, soberania e produto.
Análises com dados reais, papers acadêmicos e lições de produção. Sem spam, sem buzzword. Um email por semana.