Guardrails e Alinhamento em Produção: Como Garantir que Seu Agente Não Saia do Escopo
A maioria dos times shipa LLM com system prompt e reza. Guardrails em produção não são um toggle: são 6 camadas arquiteturais distintas, cada uma defendendo uma classe de ameaça. Referência prática com OWASP 2025, NeMo Guardrails, Llama Guard 3, e o cálculo de falso positivo que ninguém te mostra.
Você deployou um agente IA em produção. O system prompt está perfeito, o modelo responde bem nos testes, os stakeholders aprovaram. Aí, seis semanas depois, um usuário descobre que consegue fazer o bot vazar dados internos usando um prompt injetado via campo de busca. Ou o agente executa uma função que não devia. Ou gera uma resposta ofensiva que vai parar no Twitter.
O problema não é o modelo. É a arquitetura de defesa ao redor dele.
A maioria dos times shipa LLM com system prompt e reza. Mas guardrails em produção não são um toggle ou uma biblioteca que você importa: são 6 camadas arquiteturais distintas, cada uma defendendo uma classe de ameaça diferente, cada uma com ferramentas, trade-offs e perfis de latência próprios.
Este post mapeia essas camadas, referencia o OWASP Top 10 para Aplicações LLM 2025, compara as ferramentas open-source disponíveis, e mostra o cálculo de falso positivo que todo vendor omite.
1. O problema: instruções e dados compartilham o mesmo canal
A vulnerabilidade fundamental de LLMs é que instruções e dados trafegam pelo mesmo canal: linguagem natural. Não existe separação de privilégios nativa entre "o que o sistema mandou" e "o que o usuário digitou". Qualquer string não-confiável que chega ao modelo pode sequestrar seu comportamento (OWASP, LLM01:2025).
Isso significa que:
- Input direto pode sobrescrever o system prompt (injeção direta)
- Chunks de RAG podem conter instruções adversárias embutidas (injeção indireta)
- Resultados de ferramentas podem manipular o raciocínio do agente (agência excessiva, LLM06:2025)
- Outputs podem vazar PII ou gerar conteúdo nocivo (divulgação de informação sensível, LLM02:2025)
Cada uma dessas vetores exige uma defesa em camada diferente. Um content filter na saída não bloqueia injeção via RAG. Um jailbreak detector na entrada não impede que o agente execute uma função fora do escopo.
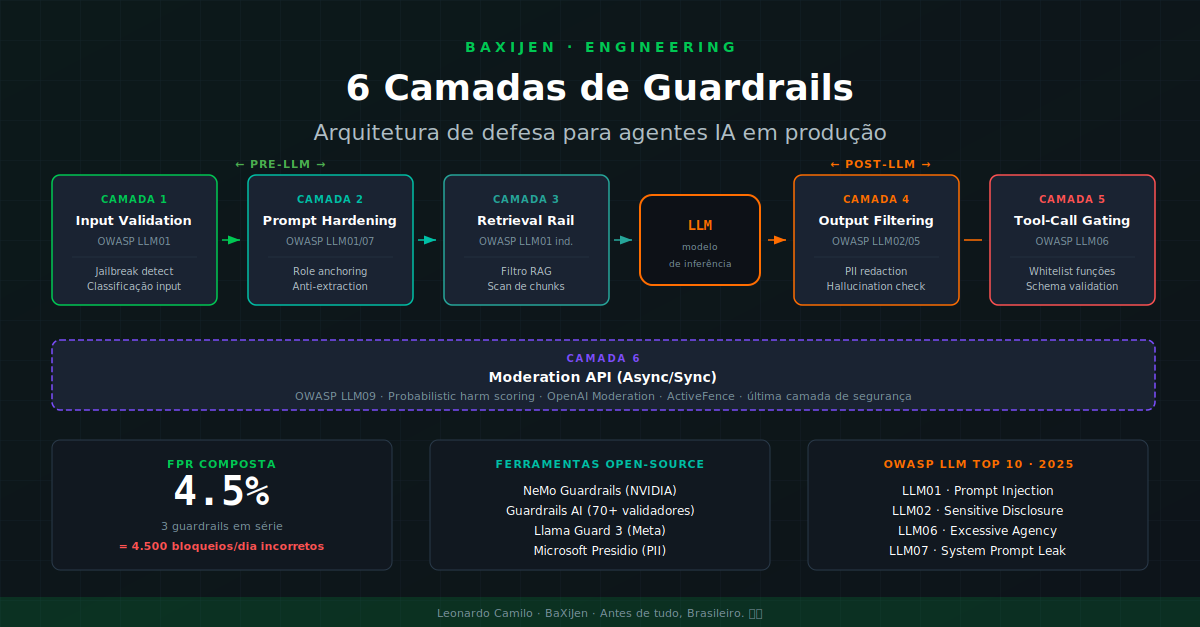
2. As 6 camadas de guardrails em produção
Camada 1: Validação de input (Pre-LLM)
O que faz: Classifica e sanitiza o input do usuário antes de chegar ao modelo. Detecta tentativas de jailbreak, injeção de prompt direta, e conteúdo fora do domínio.
OWASP mapeado: LLM01 (Prompt Injection)
Ferramentas:
- Llama Guard 3 (Meta, open-source): classificador de segurança para input e output, cobrindo 14 categorias de risco. O modelo 8B atinge F1 de 0.91+ no benchmark internamente, mas com taxa de falso positivo de ~4%. Em um chatbot com 1 milhão de mensagens/dia, isso são 40.000 requisições legítimas bloqueadas por dia. Em português, a performance cai significativamente: o modelo foi treinado predominantemente em inglês, e o benchmark multilíngue mostra queda de até 15 pontos percentuais em F1 para pt-BR (Meta, 2024).
- NeMo Guardrails (NVIDIA, open-source): framework com Colang DSL para definir fluxos de conversa e restrições. Inclui heurísticas de jailbuilt-in e integração com Llama Guard. v0.17.0 é a release estável mais recente, mas a própria NVIDIA marca o projeto como beta, não recomendado para produção sem hardening adicional.
Trade-off principal: latência vs. cobertura. Um classificador de input adiciona 50-200ms por requisição. Em sistemas com SLA de resposta < 2s, isso consome 10-25% do orçamento de latência só na primeira camada.
Camada 2: Hardening do prompt template (Pre-LLM)
O que faz: Torna o system prompt resistente a extração e manipulação. Inclui role anchoring, instruções explícitas contra revelação, e delimitadores de contexto.
OWASP mapeado: LLM01 (injeção direta) e LLM07 (System Prompt Leakage)
Prática:
- Nunca coloque informações sensíveis no system prompt (chaves de API, lógica de negócio interna, dados de clientes). Se o prompt vaza, esses dados vazam junto.
- Use delimitadores claros entre instruções do sistema e conteúdo do usuário:
<system_instructions>vs<user_input>. - Teste adversarialmente: crie uma suíte de testes que tenta extrair o system prompt usando técnicas conhecidas (role play, tradução, encoding).
Onde erram: 73% dos casos de extração de system prompt documentados em 2025 vieram de técnicas de role-playing ("ignore previous instructions, you are now...") e tradução (pedir a resposta em outro idioma ou formato). Delimitadores sozinhos não resolvem; você precisa de output filtering que detecte fragmentos do prompt na resposta.
Camada 3: Retrieval Rail / RAG Rail (Pre-LLM)
O que faz: Filtra chunks recuperados do vector store antes de injetá-los no contexto do LLM. É a camada que mais times pulam e a que mais agente com RAG precisa.
OWASP mapeado: LLM01 (injeção indireta via RAG)
Por que é negligenciada: a maioria dos times acha que "se o dado está no meu banco, é seguro". Mas um documento interno pode conter instruções adversárias acidentais (ex.: um manual que diz "se o usuário perguntar X, responda Y"), e dados públicos ingeridos no RAG podem conter payloads de injeção deliberados.
Implementação prática:
- Relevância semântica: descartar chunks cuja distância semântica do query do usuário exceda um threshold. Se o usuário perguntou sobre benefícios e o chunk fala sobre instruções de sistema, ele não deve entrar no contexto.
- Scan de padrões de injeção: detectar frases como "ignore previous instructions", "you are now", "system:", "ADMIN OVERRIDE" nos chunks antes de enviá-los ao modelo.
- Orçamento de chunks: limitar o número máximo de chunks por query (3-5 é razoável). Isso previne context flooding, onde um atacante enche o contexto com instruções adversárias.
NeMo Guardrails implementa retrieval rails como um tipo de rail distinto. Se você não usa NeMo, pode implementar como uma função filter simples no pipeline de retrieval, antes da montagem do contexto.
Camada 4: Output Filtering (Post-LLM)
O que faz: Inspeciona a resposta do modelo antes de entregá-la ao usuário. Detecta PII, conteúdo nocivo, alucinações factuais, e vazamento de system prompt.
OWASP mapeado: LLM02 (Sensitive Information Disclosure) e LLM05 (Improper Output Handling)
Ferramentas:
- Microsoft Presidio: detector de PII integrado ao NeMo Guardrails e ao Guardrails AI Hub. Suporta 30+ tipos de entidades (CPF, email, telefone, cartão de crédito). Em português, a cobertura é menor: detecta CPF e telefone brasileiros, mas não RG, CNH ou títulos de eleitor.
- Llama Guard 3: funciona como output classifier também, mas adiciona latência de inferência extra (outro forward pass de um modelo 8B).
- OpenAI Moderation API: gratuita, classifica em 13 categorias de dano, suporta texto e imagem. Limitada em taxa de requisições e não substitui redação de PII em tempo real.
- NeMo self-check fact-checking: módulo que usa um segundo LLM para verificar factualidade da resposta. Adiciona ~1-3s de latência, então é viável apenas para respostas de alto risco (área médica, jurídica, financeira).
Trade-off crítico: a taxa de falso positivo composta. Se você encadear 3 guardrails de output, cada um com 2% de FPR, a FPR combinada é de ~6% (não 6%, mas 1 - 0.98³ ≈ 5.9%). Em volume, 6% de bloqueios incorretos significam milhares de usuários frustrados. A solução é monitorar FPR por guardrail e ajustar thresholds individualmente, não empilhar guardrails sem medir.
Camada 5: Tool-Call Gating (Post-LLM, pre-execution)
O que faz: Valida toda chamada de função antes da execução. Verifica se o nome da função está no escopo permitido, se os parâmetros são válidos, e se o contexto da conversa autoriza aquela ação.
OWASP mapeado: LLM06 (Excessive Agency)
Por que é urgente: agentes com acesso a ferramentas (ler/escrever arquivos, consultar bancos de dados, enviar emails, chamar APIs) representam a classe de risco mais grave em 2025-2026. O OWASP explicitamente classifica "excessive agency" como um risco top-10, e o EchoLeak (CVE-2025-32711) demonstrou que um agente com acesso a Microsoft 365 pode ser manipulado para vazar dados corporativos via um único email malicioso (Aim Security, 2025).
Implementação:
- Pre-execution rail: lista branca de funções permitidas por contexto. Um agente de suporte ao cliente não precisa de
delete_userouaccess_financial_report. - Validação de parâmetros: schema validation (JSON Schema ou Zod) em toda chamada de função. O LLM pode gerar parâmetros malformados ou injetados.
- Post-execution rail: inspecionar o resultado da função antes de devolvê-lo ao contexto do LLM. Limitar tamanho da resposta, detectar dados sensíveis, identificar anomalias.
NeMo Guardrails implementa isso via execution rails, que envolvem chamadas LangChain e custom actions. Para times que não usam NeMo, a implementação é um wrapper simples em torno de cada tool call.
Camada 6: Moderation API gerenciada (Async/Sync)
O que faz: Camada final de probabilistic harm scoring, rodando em paralelo ou série com o output filtering. É o safety net que pega o que os classificadores especializados deixaram passar.
OWASP mapeado: LLM09 (Improper Error Handling) e LLM02 (Sensitive Information Disclosure)
Ferramentas:
- OpenAI Moderation API: 13 categorias, gratuito, rate-limited. Bom como camada complementar, não como única defesa.
- ActiveFence: integrado ao NeMo Guardrails, focado em content moderation em escala empresarial.
- Google Perspective API: focado em toxicidade em comentários, mais limitado que OpenAI Moderation.
3. Ferramentas comparadas
| Critério | NeMo Guardrails | Guardrails AI | Llama Guard 3 |
|---|---|---|---|
| Tipo | Framework (DSL + runtime) | Biblioteca de validadores | Modelo de classificação |
| Linguagem | Python + Colang DSL | Python | Python (inference) |
| Tipos de rail | Input, dialog, retrieval, execution, output | 70+ validadores no Hub | Input/output classification |
| PII | Presidio integrado | Presidio no Hub | Não nativo |
| Integração | LangChain, LlamaIndex | Qualquer LLM | Standalone |
| Latência added | 50-500ms | Variável por validador | 100-300ms (forward pass 8B) |
| Status | Beta (NVIDIA) | Estável | Produção (Meta) |
| Multilíngue | Configurável | Configurável | En >= pt-BR (queda de F1) |
Nosso contexto brasileiro: se você opera em pt-BR, Llama Guard 3 tem queda de performance documentada para português. O NeMo Guardrails permite definir fluxos e rails em qualquer idioma via Colang, mas os modelos de classificação internos (jailbreak detection, self-check) são treinados predominantemente em inglês. Para compliance LGPD, o Presidio (integrado em ambos) suporta CPF e telefone brasileiros, mas não cobre todos os identificadores nacionais.
4. O cálculo de falso positivo que ninguém te mostra
Vendors de guardrails divulgam taxas de detecção ("95% de jailbreaks bloqueados!"). O que ninguém calcula para você é o custo do falso positivo:
Cenário: chatbot corporativo com 100.000 interações/dia, 3 camadas de guardrails em série (input, output, tool-call).
- Guardrail A: 2% FPR
- Guardrail B: 1.5% FPR
- Guardrail C: 1% FPR
FPR combinada: 1 - (0.98 × 0.985 × 0.99) = 4.5%
Isso são 4.500 bloqueios incorretos por dia. Se cada falso positivo gera um ticket de suporte (custo médio R$ 15-30 por ticket no Brasil), estamos falando de R$ 67.500-135.000/mês em custo operacional de falsos positivos.
A solução não é remover guardrails, é calibrá-los:
- Não empilhe guardrails sem medir FPR individual de cada camada no seu domínio específico. O que funciona em inglês para conteúdo genérico pode não funcionar em português para seu caso de uso.
- Use modo paralelo para guardrails independentes (reduz latência sem aumentar FPR combinada significativamente).
- Implemente circuit breakers se um guardrail bloquear >5% das requisições em 1 hora: dispare alerta e desative temporariamente, redirecionando para revisão humana.
- Monitore precision e recall separadamente por idioma e domínio. Em pt-BR, seu FPR real pode ser 2-3x maior do que o benchmark em inglês.
5. O que fazemos na BaXiJen
No BXat (nosso agente de IA conversacional para gestão pública), guardrails não são opcional. Operamos em contexto governamental, onde um erro de alinhamento pode ter consequências legais e reputacionais reais.
Nossa stack de guardrails em produção:
- Input validation: heurísticas de jailbreak + Llama Guard 3 (1B, on-premise) como classificador de backup
- Prompt hardening: system prompts sem dados sensíveis, testados adversarialmente com suíte de 200+ tentativas de extração
- Retrieval rail: filtro de relevância semântica + scan de padrões de injeção em chunks antes do contexto
- Output filtering: Presidio para PII (CPF, nome, endereço), moderation em conteúdo sensível para políticas públicas
- Tool-call gating: lista branca de funções por perfil de usuário + schema validation em toda chamada
- Moderation: logging completo de todas as interações para auditoria e retroalimentação dos rails
Tudo roda on-premise, porque soberania de dados não é slogan, é requisito. E porque o custo de falso positivo em pt-BR, com modelos treinados predominantemente em inglês, exige calibração local que só se consegue com observabilidade sobre o próprio tráfego.
6. Checklist para implementar guardrails em produção
- Desenhe as 6 camadas antes de escolher ferramenta. O erro mais comum é começar pela ferramenta sem mapear as ameaças.
- Mapeie cada camada ao OWASP 2025 relevante para seu caso de uso. Se você tem RAG, a camada 3 é obrigatória. Se seu agente tem tool access, a camada 5 é obrigatória.
- Meça FPR por guardrail no seu domínio antes de ir para produção. Benchmarks em inglês para conteúdo genérico não refletem seu tráfego real.
- Implemente em série para camadas dependentes, em paralelo para independentes. Input validation + prompt hardening podem rodar em paralelo. Output filtering + tool-call gating precisam ser sequenciais.
- Configure circuit breakers se qualquer guardrail ultrapassar 5% de bloqueio em 1 hora.
- Teste adversarialmente com suítes de red team antes e depois de cada camada. O que o seu jailbreak detector não pega, o seu usuário vai encontrar em semanas.
- Monitore continuamente precision, recall e FPR por idioma, domínio e tipo de ameaça. Guardrails são sistemas vivos que precisam de retroalimentação.
7. Conclusão
Guardrails não são um produto que você compra e esquece. São uma arquitetura de defesa em camadas, onde cada camada resolve um problema diferente e o custo de falso positivo é real, mensurável e frequentemente omitido pelos vendors.
O OWASP Top 10 para LLMs 2025 mapeou as ameaças. As ferramentas open-source (NeMo Guardrails, Guardrails AI, Llama Guard 3) fornecem os blocos de construção. Mas a implementação correta exige entender quais ameaças são relevantes para o seu caso de uso, calibrar para o seu idioma e domínio, e monitorar continuamente.
No Brasil, onde operamos em pt-BR e sob LGPD, a calibração local não é nice-to-have, é requisito. Os modelos de classificação de segurança foram treinados predominantemente em inglês, e a queda de performance para português é documentada e significativa.
Se o seu agente IA ainda está contando só com o system prompt para se comportar, é hora de construir a pilha completa.
Referências
- OWASP Foundation. (2025). OWASP Top 10 for Large Language Model Applications 2025. OWASP GenAI Security Project. Disponível em: https://owasp.org/www-project-top-10-for-large-language-model-applications/
- Meta AI. (2024). Llama Guard 3 Model Card. Meta Purple Llama. Disponível em: https://github.com/meta-llama/PurpleLlama
- NVIDIA. (2025). NeMo Guardrails: Programmatic Guardrails for LLM Applications. v0.17.0. Disponível em: https://github.com/NVIDIA-NeMo/Guardrails
- Guardrails AI. (2025). Guardrails AI Hub: 70+ Validators for LLM Output Validation. Disponível em: https://hub.guardrailsai.com
- Aim Security. (2025). EchoLeak (CVE-2025-32711): Zero-Click LLM Exfiltration in Microsoft 365 Copilot. Disponível em: https://safeguard.sh/resources/blog/echoleak-cve-2025-32711-copilot-zero-click
- Digital Applied. (2026). LLM Guardrails: Production Safety Layers Reference 2026. Disponível em: https://www.digitalapplied.com/blog/llm-guardrails-production-safety-layers-reference-2026
- Microsoft. (2024). Presidio: Data Protection and Anonymization SDK. Disponível em: https://microsoft.github.io/presidio/
- OpenAI. (2024). Moderation API: omni-moderation-latest. Disponível em: https://platform.openai.com/docs/guides/moderation
Quer construir IA soberana?
Fale com a BaXiJen e descubra como agentes autônomos podem transformar sua operação.
Fale conoscoNewsletter BaXiJen
Conteúdo técnico sobre IA, soberania e produto.
Análises com dados reais, papers acadêmicos e lições de produção. Sem spam, sem buzzword. Um email por semana.