Avaliação de LLMs e agentes IA em produção: o guia que ninguém te dá
Seu modelo passou no benchmark. Mas será que funciona de verdade com dados reais? Um guia prático sobre como avaliar LLMs, RAG e agentes IA em produção: métricas que importam, armadilhas dos benchmarks, LLM-as-judge e por que golden datasets são o ouro do seu pipeline.
Avaliação de LLMs e agentes IA em produção: o guia que ninguém te dá
Seu modelo passou no MMLU. No HumanEval. No GSM8K. Você comemorou, deployou e, duas semanas depois, os usuários reclamam: respostas erradas, alucinações, custos fora do controle. O que aconteceu?
O que aconteceu é que benchmarks acadêmicos medem uma coisa e a produção exige outra. E entre os dois, existe um abismo que a maioria dos times descobre só depois do primeiro incidente.
Este post é o guia que eu queria ter lido antes de colocar SLMs em produção para gestão pública. Vou falar de métricas que importam de verdade, armadilhas que repeti até aprender e como montar um pipeline de avaliação que funciona.
O problema dos benchmarks
Benchmarks como MMLU, GSM8K e HumanEval são úteis para comparação entre modelos, mas têm limitações sérias quando o assunto é produção:
-
Domínio específico: um modelo que acerta 90% no MMLU pode ter 40% de acurácia no seu domínio. Pesquisa de Yehudai et al. (2025) mostrou que benchmarks de agentes IA cobrem apenas parcialmente as capacidades exigidas em fluxos reais, com gaps críticos em custo-eficiência, segurança e robustez (Yehudai et al., 2025).
-
Contaminação de dados: muitos modelos são treinados ou ajustados em dados que vazam para os benchmarks, inflando resultados artificialmente. O Lxt AI reportou em 2026 que, dos 15 benchmarks ativos, apenas 4 preveem resultados de produção de forma confiável.
-
Métricas desconectadas do negócio: acurácia em múltipla escolha não diz se o usuário vai continuar usando seu produto. O que importa é: a resposta foi útil? foi confiável? chegou rápido o suficiente?
A conclusão é simples: benchmarks são necessários mas não suficientes. Eles dizem se um modelo é capaz de algo, não se ele entrega isso na sua aplicação específica.
Avaliação offline: seu golden dataset é seu ativo mais valioso
Antes de qualquer coisa, você precisa de um golden dataset: um conjunto de exemplos curados com perguntas, contextos e respostas esperadas que representam o uso real do seu sistema.
Como construir um golden dataset
Não comece gerando dados sintéticos. Comece com logs reais:
- Colete: pegue as 200-500 interações mais representativas dos seus usuários reais. Em produção, isso significa habilitar logging estruturado desde o dia 1.
- Curate: anote manualmente qual seria a resposta ideal para cada pergunta. Isso é trabalho braçal, mas é o que separa avaliação séria de achismo.
- Categorize: divida em categorias que fazem sentido para o seu negócio (perguntas factuais, instrucionais, criativas, edge cases).
- Atualize: o dataset cresce com o tempo. Adicione exemplos de falhas reais e edge cases que surgem em produção.
Para sistemas RAG, o framework RAGAS (Shahul et al., 2023) define quatro métricas fundamentais:
| Métrica | O que mede | Como calcular |
|---|---|---|
| Faithfulness | A resposta é fiel ao contexto recuperado? | Divide a resposta em claims e verifica se cada uma é suportada pelo contexto |
| Answer Relevancy | A resposta é relevante para a pergunta? | Gera perguntas possíveis a partir da resposta e mede similaridade com a pergunta original |
| Context Precision | Os trechos recuperados são relevantes? | Verifica se os trechos rankeados mais alto são os mais úteis |
| Context Recall | O contexto recuperado cobre tudo que precisava? | Compara a resposta ground-truth com os trechos disponíveis |
Essas métricas são complementares, não substitutas. Um sistema com alta faithfulness mas baixa answer relevancy está gerando respostas fiéis que não respondem o que foi perguntado. Alta relevância com baixa faithfulness está alucinando de forma convincente.
Métricas de retrieval que importam
Antes de chegar na geração, o retrieval precisa funcionar. As métricas clássicas de information retrieval são essenciais:
- Recall@K: dos K documentos retornados, quantos dos relevantes estão incluídos? Essencial para garantir que o contexto necessário está disponível.
- MRR (Mean Reciprocal Rank): em que posição aparece o primeiro documento relevante? Quanto menor, melhor.
- nDCG (Normalized Discounted Cumulative Gain): considera a relevância graduada e a posição. Ideal quando nem todos os documentos são igualmente relevantes.
Para SLMs em português, esses números caem significativamente em relação ao inglês. No BXat, observamos recall@5 de 0.78 em consultas em inglês caindo para 0.62 em português, principalmente por limitações do chunking e embeddings multilíngues.
LLM-as-Judge: quando um modelo avalia outro
A ideia de usar um LLM para avaliar outro é tentadora e, na prática, inevitável para escalabilidade. Zheng et al. (2023) demonstraram que GPT-4 como juiz alcança mais de 80% de concordância com avaliadores humanos no MT-Bench, o mesmo nível de concordância entre humanos.
Mas a pesquisa de Oriyad et al. (2025) mostrou que LLMs-as-judge sofrem de shortcut bias: tendem a preferir respostas mais longas, mais formais ou que usam mais jargão técnico, independentemente da correção factual. Isso é particularmente perigoso quando o modelo avaliado e o juiz vêm do mesmo ecossistema.
Boas práticas para LLM-as-Judge
- Use um modelo diferente: se avalia Qwen, use Llama como juiz (ou vice-versa). Modelos da mesma família tendem a concordar entre si por viés compartilhado.
- Prompt estruturado: defina critérios claros e numéricos. "Avalie de 1 a 5 a fidelidade ao contexto, onde 1 é completamente infiel e 5 é perfeitamente fiel" é melhor que "essa resposta é boa?".
- Blind evaluation: apresente as respostas sem identificar qual modelo gerou. Evita viés de ancoragem.
- Calibre com humanos: faça amostragem e compare com avaliação humana periodicamente. Se o juiz está divergindo dos humanos, recalibre.
- Não use como única fonte: LLM-as-judge é uma ferramenta, não substituição. Combine com métricas determinísticas e avaliação humana.
Para SLMs, o custo-benefício é favorável. Avaliar 1000 respostas com GPT-4 como juiz custa aproximadamente US$ 15-30, enquanto avaliação humana equivalente custaria US$ 500-1000. Mas para português brasileiro, a concordância cai para 70-75%, exigindo mais calibração.
Avaliação online: métricas que você monitora em produção
Enquanto a avaliação offline garante que o sistema pode funcionar, a online garante que está funcionando. As métricas se dividem em três categorias:
Métricas de qualidade
- Hallucination rate: porcentagem de respostas com informações não suportadas pelo contexto. Monitore com LLM-as-judge em amostragem.
- Answer completeness: a resposta cobre todos os aspectos da pergunta? Meça com rubricas definidas por domínio.
- Retrieval failure rate: com que frequência o sistema não encontra contexto relevante? Quando isso acontece, a resposta inevitavelmente sai do contexto.
Métricas de eficiência
- Latência p50/p95/p99: tempo de resposta nos percentis 50, 95 e 99. Para chatbots de atendimento público, o p95 precisa estar abaixo de 5 segundos.
- Custo por interação: tokens in + tokens out × preço. Com SLMs, isso cai de US$ 0.03-0.10 por interação (GPT-4) para US$ 0.001-0.005 (Qwen2.5-7B local).
- Throughput: requisições por segundo por GPU. Essencial para dimensionamento.
Métricas de satisfação
- Thumbs up/down: simples e direto. Se o usuário não volta ou reclama, a métrica técnica não importa.
- Task completion rate: o usuário conseguiu fazer o que queria? Para BXat na gestão pública, medimos se o gestor encontrou a informação que precisava para tomar uma decisão.
- Escalation rate: com que frequência o usuário precisa ser transferido para um humano? Taxa alta indica limitação do sistema.
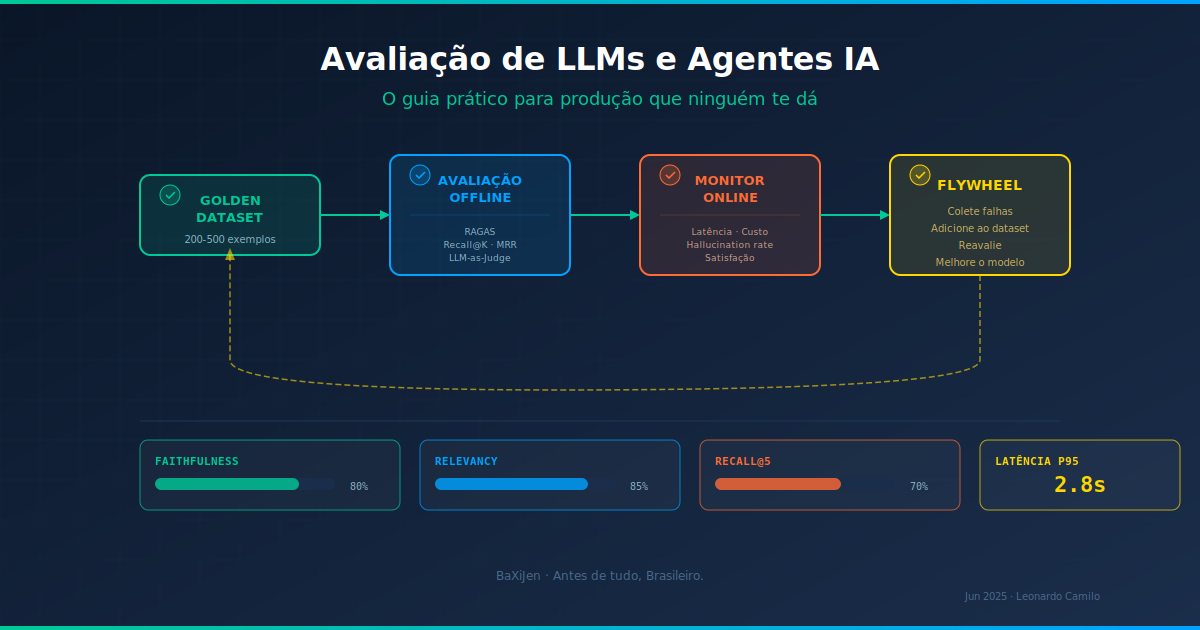
O pipeline completo: offline + online + LLM-as-judge
Montar avaliação não é um passo, é um processo contínuo. O ciclo é:
- Construa seu golden dataset com dados reais do seu domínio.
- Avalie offline com RAGAS + métricas de retrieval + LLM-as-judge antes de qualquer deploy.
- Monitore online com métricas de qualidade, eficiência e satisfação em produção.
- Colete falhas e adicione ao golden dataset. Cada bug é um caso de teste futuro.
- Reavalie após cada mudança de modelo, prompt ou retrieval.
Esse ciclo cria um flywheel: quanto mais você avalia, melhor fica o dataset, mais precisa fica a avaliação, mais rápido você identifica problemas.
Tabela de referência: ferramentas de avaliação
| Ferramenta | Tipo | Uso principal | Custo |
|---|---|---|---|
| RAGAS | Framework open-source | Avaliação de pipelines RAG (faithfulness, relevancy) | Gratuito (self-hosted) |
| LangSmith | Plataforma comercial | Tracing + avaliação + datasets | Freemium |
| Langfuse | Plataforma open-source | Observabilidade + evals + prompts | Gratuito (self-hosted) |
| OpenAI Evals | Framework open-source | Avaliação genérica de LLMs | Gratuito (pagam chamadas API) |
| Promptfoo | CLI open-source | Avaliação comparativa de prompts/modelos | Gratuito |
| DeepEval | Framework open-source | Métricas sintéticas + LLM-as-judge | Gratuito |
Para times brasileiros rodando SLMs locais, a combinação RAGAS + Langfuse + Promptfoo cobre o espectro completo sem custo de licença.
O que ninguém te conta sobre avaliação
1. Seu golden dataset vicia
Se você sempre avalia nos mesmos exemplos, otimiza para eles. A solução é ter holdout sets que só usa para validação final, nunca para ajuste de prompt ou retrieval.
2. Métricas de LLM em português são piores
Modelos como juiz performam pior em português do que em inglês. Pesquisas de Yehudai et al. (2025) e Ferrag et al. (2025) mostram que benchmarks para agentes ainda são predominantemente em inglês e cobrem cenários que não refletem a realidade de mercados emergentes. Adapte os prompts de avaliação e crie exemplos no seu idioma.
3. Avaliação é investimento, não custo
Um pipeline de avaliação robusto reduz o tempo entre deploy e detecção de problemas de dias para horas. Para startups, isso é a diferença entre perder um cliente e corrigir antes que ele perceba.
4. Nenhum benchmark substitui o feedback do usuário
Thumbs up/down, taxas de retenção e reclamações diretas são a métrica final. Se o benchmark diz 95% e o usuário diz "não presta", acredite no usuário.
Conexão com a BaXiJen
Na BaXiJen, avaliação é parte do produto. O BXat para gestão pública é avaliado não por benchmarks genéricos, mas por métricas que importam para o gestor público: a resposta estava correta? o gestor encontrou o que precisava? em quanto tempo? O golden dataset do BXat inclui perguntas reais de gestores sobre licitações, contratos e transparência, coisas que nenhum benchmark internacional cobre.
Avaliar bem é tão importante quanto construir bem. E se você está colocando IA em produção sem um pipeline de avaliação, está voando cego.
Referências
-
Ferrag, M. A., Tihanyi, N., & Debbah, M. (2025). From LLM Reasoning to Autonomous AI Agents: A Comprehensive Review. arXiv preprint arXiv:2504.19678.
-
Mohammadi, M., Li, Y., Lo, J.-P., & Yip, W. (2025). Evaluation and Benchmarking of LLM Agents: A Survey. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining.
-
Oriyad, A. M., Rohban, M. H., & Baghshah, M. (2025). The Silent Judge: Unacknowledged Shortcut Bias in LLM-as-a-Judge. arXiv preprint arXiv:2509.26072.
-
Shahul, E. S., James, J., Espinosa Anke, L., & Schockaert, S. (2023). RAGAs: Automated Evaluation of Retrieval Augmented Generation. arXiv preprint arXiv:2309.15217.
-
Yehudai, A., Eden, L., Li, A., Uziel, G., Zhao, Y., Bar-Haim, R., Cohan, A., & Shmueli-Scheuer, M. (2025). Survey on Evaluation of LLM-based Agents. arXiv preprint arXiv:2503.16416.
-
Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, D., & Xing, E. (2023). Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. NeurIPS.
Quer construir IA soberana?
Fale com a BaXiJen e descubra como agentes autônomos podem transformar sua operação.
Fale conoscoNewsletter BaXiJen
Conteúdo técnico sobre IA, soberania e produto.
Análises com dados reais, papers acadêmicos e lições de produção. Sem spam, sem buzzword. Um email por semana.