Data Flywheel: Como Agentes que Aprendem com Uso Superam Modelos Estáticos
Modelos estáticos degradam com o tempo porque o mundo muda mais rápido que o treinamento. Data flywells fecham esse ciclo: cada interação em produção vira sinal de melhoria, e cada melhoria gera interações melhores. Este artigo mapeia a anatomia de um flywheel de produção, os sinais explícitos e implícitos que alimentam o ciclo, as quatro alavancas de melhoria e por que a maioria dos flywheels trava no terceiro mês.
Você treinou seu modelo. Fez o deploy. As métricas estão boas. E então, semana a semana, a acurácia cai. Não porque o código quebrou, mas porque o mundo mudou e o modelo continuou o mesmo.
Um agente de atendimento ao cliente treinado na documentação de produto de janeiro não sabe que o plano premium mudou em março. Um agente de compliance que nunca viu a nova redação da LGPD não consegue orientar sobre as atualizações. O problema não é o modelo: é a ausência de ciclo de melhoria.
O conceito de data flywheel descreve exatamente isso: um sistema em que cada interação em produção gera sinais de melhoria, esses sinais alimentam o modelo, o modelo melhora, e cada nova interação é um pouco melhor que a anterior. A diferença entre um agente com flywheel e um sem é a diferença entre um sistema que aprende e um sistema que apenas executa.
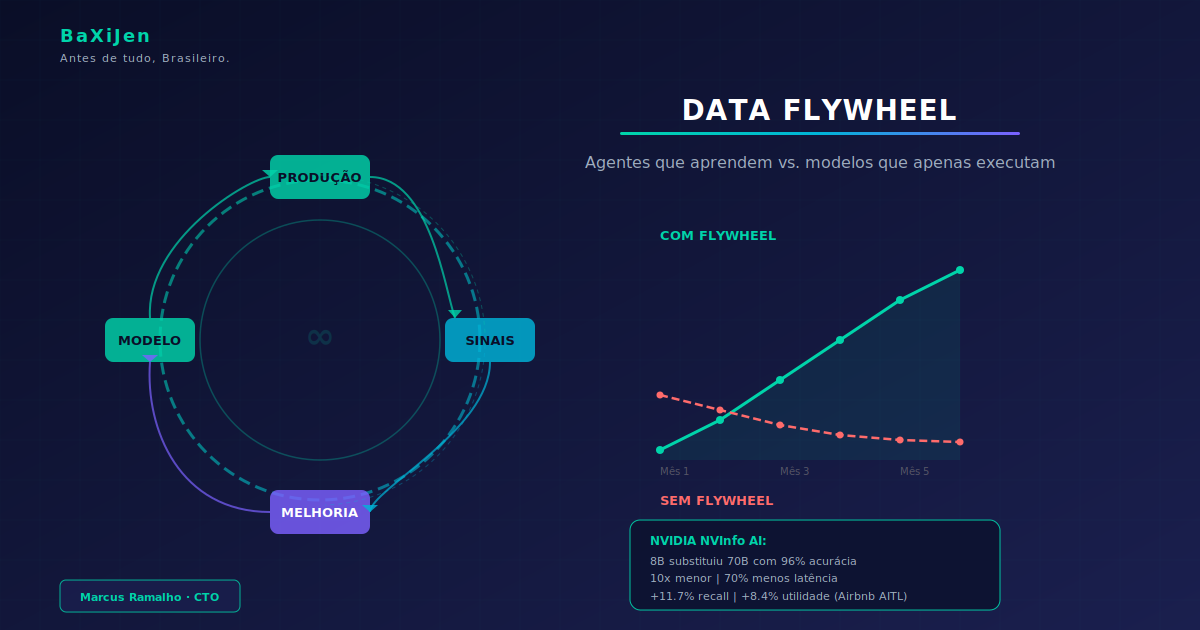
A NVIDIA documentou o caso do NVInfo AI, seu assistente de conhecimento interno que serve mais de 30.000 funcionários. Em três meses de produção com um flywheel estruturado, a equipe coletou 495 amostras negativas, identificou dois modos de falha dominantes (erros de roteamento: 5,25% e erros de reformulação de queries: 3,2%), e aplicou fine-tuning direcionado. Resultado: o modelo de roteamento passou de Llama 3.1 70B para um modelo fine-tuned de 8B com 96% de acurácia, redução de 10x no tamanho e 70% de melhoria em latência (Shukla et al., 2025, arXiv:2510.27051).
Este artigo mapeia por que modelos estáticos degradam, como funciona a anatomia de um data flywheel de produção, quais sinais alimentam o ciclo, as quatro alavancas de melhoria e os modos de falha que fazem a maioria dos flywheels travar.
1. Por que modelos estáticos degradam
Modelos de linguagem treinados em datasets fixos são instantâneos de um mundo que continua mudando. Um agente de suporte treinado na documentação do último trimestre não sabe que o plano premium mudou na semana passada. A distribuição do tráfego real diverge progressivamente da distribuição de treino: consultas novas, edge cases e combinações inéditas surgem a cada semana de operação.
O estudo do Airbnb (Dai et al., 2025, arXiv:2510.06674) sobre o framework Agent-in-the-Loop (AITL) quantificou o problema: em cenários de suporte ao cliente, políticas de produto mudam continuamente, preferências dos usuários evoluem, e a base de conhecimento relevante se desloca. Sem um mecanismo de retroalimentação, o modelo se torna progressivamente menos útil sem que ninguém perceba até que as escaladas de suporte disparem ou o NPS despence.
A degradação é composta. A cada semana de deploy sem retr treino, três coisas acontecem simultaneamente: a distribuição de queries reais se afasta da distribuição de treino; o modelo não aprende com os novos padrões de uso; e os casos de borda acumulados criam buracos de cobertura que só crescem. O modelo não quebra de uma vez. Ele escurece aos poucos.
2. Anatomia de um data flywheel
Um data flywheel é, na essência, um ciclo de retroalimentação auto-reforçante: produção gera sinais, sinais viram dados de treino, dados de treino melhoram o modelo, modelos melhores geram interações melhores, que geram sinais melhores. Cada revolução compõe sobre a anterior.
A arquitetura de um flywheel de produção tem cinco componentes:
- Coleta de sinais: capturar sinais explícitos e implícitos de cada interação em produção
- Filtragem e curadoria: separar sinal de ruído, deduplicar, estratificar
- Treino e refinamento: usar os dados curados para fine-tuning, distilação ou ajuste de prompt
- Avaliação: validar que o modelo melhorou nos critérios relevantes antes de promover
- Deploy e monitoramento: colocar o modelo melhorado em produção e reiniciar o ciclo
O pulo do gato está na transição entre os estágios. A maioria dos times consegue coletar dados, mas poucos conseguem transformar esses dados em melhorias mensuráveis. E ainda menos conseguem fazer isso de forma contínua e automatizada.
2.1 Os quatro estágios de maturidade do flywheel
A pesquisa da Zylos (2026) sobre data flywheels em produção mapeou quatro estágios de maturidade:
Estágio 1: Monitoramento ad hoc. Times acompanham métricas agregadas (acurácia, CSAT, taxa de escalada), mas não têm coleta sistemática de feedback. Quando a performance degrada, engenheiros revisam logs manualmente para diagnosticar falhas.
Estágio 2: Feedback explícito. Thumbs up/down, interfaces de correção e pesquisas de satisfação fornecem exemplos rotulados de sucessos e falhas. O ciclo de feedback roda mensalmente, com curadoria manual de dados antes de cada ciclo de retr treino.
Estágio 3: Sinais implícitos. A equipe instrumenta a produção para capturar sinais comportamentais: usuários que reformulam queries indicam falha, usuários que copiam a resposta indicam sucesso, usuários que abandonam a conversa indicam frustração. Esses sinais implícitos escalam muito além do que interfaces de rating explícito conseguem coletar.
Estágio 4: Melhoria contínua automatizada. Coleta de feedback, curadoria de dados, treino, avaliação e deploy ocorrem em pipeline automatizada com intervenção humana mínima. A revisão humana é reservada para decisões de alto risco e adjudicação de edge cases. Ciclos de retr treino encolhem de meses para dias.
A maioria das organizações em 2026 está entre os estágios 2 e 3. Migrar para o estágio 4 exige investimento em infraestrutura, governança de dados e confiança organizacional que muitos times ainda não estão prontos para fazer.
3. Sinais explícitos: a base do flywheel
Sinais explícitos são os mais confiáveis porque codificam preferência humana diretamente. Mas são escassos: menos de 1% das interações em produção geram feedback explícito (Tian Pan, 2025). Formas elaboradas de feedback alcançam 95% de abandono. Um simples thumbs up/down inline aumenta submissões de feedback em 40x comparado a formulários modais.
Os principais mecanismos:
Ratings binários. Thumbs up/down anexados a respostas do agente. Baixo atrito para coletar, mas rótulos binários carregam pouca informação e sofrem de viés de seleção: usuários que se dão ao trabalho de avaliar são sistematicamente diferentes dos que não avaliam.
Ratings comparativos. Mostrar ao usuário duas respostas candidatas e perguntar qual prefere (o paradigma RLHF) extrai sinal mais rico que ratings binários. É particularmente eficaz para avaliar diferenças de qualidade sutis que julgamentos binários perdem.
Captura de correções. Quando usuários editam um rascunho gerado pelo agente, o diff entre a versão original e a editada codifica um sinal de preferência granular. Sistemas como GitHub Copilot mineraram dados de correção em escala, embora considerações de privacidade em torno de sugestões de código exijam governança cuidadosa.
Tracking de adoção. O framework AITL do Airbnb (Dai et al., 2025) capturou quatro categorias de feedback explícito embebidas no fluxo de trabalho de suporte ao vivo: preferência pareada entre respostas, adoção/rejeição com justificativas, avaliação de relevância de conhecimento e sinalização de lacunas de conhecimento. Esses quatro tipos de sinal, incorporados diretamente no fluxo de trabalho, geraram melhorias mensuráveis: +11,7% em recall de recuperação, +8,4% em utilidade das respostas e +4,5% em adoção pelo agente, comprimindo ciclos de retr treino de meses para semanas.
4. Sinais implícitos: escalando além da anotação manual
Sinais implícitos são capturados passivamente a partir de traces comportamentais, escalando para toda interação sem burden adicional de anotação. O volume é muito maior, mas a relação sinal-ruído é menor. A chave é triangulação: nunca otimize um sinal isolado.
Aqui está o que os sinais comportamentais mais comuns indicam:
| Sinal | Indica |
|---|---|
| Usuário copia a resposta | Sucesso: a resposta foi útil o suficiente para usar |
| Usuário aceita sugestão sem edição | Sucesso: a resposta atendeu à necessidade |
| Usuário reformula a mesma query | Falha: a resposta não resolveu |
| Usuário envia correção ("não é isso") | Falha: houve erro de compreensão |
| Usuário abandona a conversa | Falha: frustração ou perda de interesse |
| Usuário edita a resposta antes de usar | Sucesso parcial: útil, mas não completa |
| Tempo excessivo de leitura antes de agir | Sinal ambíguo: pode ser reflexão ou confusão |
O caso da Zapier é ilustrativo. Sinais fortes positivos: usuários habilitando um agente após uma sessão de teste, delegando workflows recorrentes com sucesso. Sinais fortes negativos: usuários pedindo ao agente para parar no meio da execução, enviando mensagens que reformulam pedidos anteriores, completando manualmente tarefas que o agente deveria ter feito.
A plataforma Raindrop (estudo de caso ZenML, 2025) demonstrou detecção semântica de falhas que vai além de matching de keywords: detectando padrões como "esquecimento do agente" (o usuário teve que repetir contexto de earlier na conversa) e "divergência de tarefa" (o agente se afastou do objetivo declarado). Esses sinais semânticos, combinados com ratings binários, fornecem sinal significativamente mais rico que qualquer um isolado.
4.1 Timing de anotação importa
Para tarefas que envolvem identificação de conhecimento faltante, anotação imediata (enquanto o contexto da interação está fresco) melhora dramaticamente as taxas de concordância. Em um sistema de produção, concordância de relevância de conhecimento saltou de 43,6% para 92,3% quando a anotação foi feita online em vez de dias depois. Para tarefas de preferência e adoção, o timing não fez diferença significativa, então batch é viável sem perda de qualidade.
5. As quatro alavancas do flywheel
Tian Pan (2025) mapeou quatro alavancas para fechar o ciclo, ordenadas da mais rápida para a mais profunda:
Alavanca 1: Melhoria de prompt (mais rápida, mais barata). Corrigir padrões de falha descobertos no monitoramento editando o system prompt. Custo zero de treino. Particularmente poderosa quando combinada com few-shot dinâmico: manter um banco de dados de exemplos rotulados de produção e, no momento da inferência, recuperar os K exemplos mais similares ao input corrente usando similaridade de embeddings. Isso é in-context learning a partir de dados reais de produção: melhoria sem retr treino.
Alavanca 2: Atualizações da base de conhecimento RAG. Quando o monitoramento revela falhas de "conhecimento faltante", o modelo não tem a informação que precisa. A solução é adicionar esse conhecimento ao corpus de recuperação. Mais complexidade de infraestrutura que edição de prompt (pipeline de embeddings, tuning de recuperação), mas sem mudança nos pesos do modelo.
Alavanca 3: Fine-tuning em dados curados de produção. O pipeline completo: registrar todos os pares prompt/completion com tags de workload_id por tipo de tarefa; deduplicar e aplicar split estratificado com conscientização de classes; curar manualmente um subconjunto para avaliação; treinar com LoRA ou QLoRA para eficiência; comparar contra baseline com métricas decompostas (acurácia factual, aderência a instruções, completude, tom); promover ou rejeitar baseado em critério quantitativo. Aviso: fine-tuning em dados ruidosos sem curadoria adequada degrada o modelo. Se o flywheel não tem filtragem, ele vira um moedor de lixo.
Alavanca 4: Distilação e substituição de modelo (mais lenta, mais profunda). O caso da NVIDIA é exemplar: um modelo Llama 3.1 70B servindo como teacher foi destilado para um modelo fine-tuned de 8B para roteamento, mantendo 96% de acurácia com redução de 10x no tamanho e 70% em latência. O blueprint de data flywheel da NVIDIA (NeMo microservices) automatiza esse processo: ingestão de logs, tagging por workload, criação de datasets, fine-tuning com LoRA, avaliação com LLM-as-judge e deploy do modelo menor promovido.
A escolha da alavanca depende da velocidade necessária e da profundidade da mudança. Prompt editing resolve em minutos problemas de instrução. Fine-tuning resolve em dias problemas de comportamento. Distilação resolve em semanas problemas de custo e latência. O erro mais comum é pular direto para fine-tuning sem antes esgotar as alavancas mais rápidas.
6. Por que a maioria dos flywheels trava no terceiro mês
A pesquisa da Zylos (2026) identificou que a maioria dos flywheels estagnam por três motivos:
1. Degradção de qualidade de anotação. Os padrões fáceis são aprendidos rapidamente nos primeiros ciclos. Depois, o que sobra são edge cases cada vez mais difíceis, e a qualidade da anotação humana degrada à medida que os anotadores enfrentam ambiguidade crescente. Sem investimento contínuo em qualidade de anotação e calibração entre anotadores, o sinal se dilui.
2. Deriva de comportamento do usuário. O comportamento dos usuários muda mais rápido que os ciclos de retr treino conseguem acompanhar. Em domínios como suporte ao cliente, políticas de produto mudam semanalmente, e o flywheel que roda mensalmente está sempre pelo menos uma atualização atrasado.
3. Fricção regulatória e de governança. Privacidade de dados, requisitos de LGPD/GDPR e o custo de anotação humana criam atrito em cada estágio do pipeline. Cada ciclo de melhoria precisa passar por revisão de compliance, o que adiciona latência e reduz a frequência dos ciclos.
A solução não é eliminar esses atritos, mas arquitetar o flywheel para operar dentro deles. Flywheels robustos combinam sinais implícitos (que escalam sem consentimento individual por serem agregados e anonimizados) com validação explícita em pontos de alto risco. Ciclos curtos de prompt engineering e atualização de RAG (alavancas 1 e 2) reduzem a dependência de ciclos longos de fine-tuning. E pipeline automatizada de avaliação com LLM-as-judge permite filtrar ruído em escala sem depender de anotação humana para cada interação.
7. Data flywheel no contexto brasileiro
Para operações de IA no Brasil, o data flywheel tem implicações específicas que vão além da arquitetura técnica:
LGPD como restrição e oportunidade. A Lei Geral de Proteção de Dados exige base legal para processamento de dados pessoais. Coletar logs de interação para retr treino requer base legal adequada (consentimento ou legítimo interesse), anonimização e políticas de retenção. Mas a LGPD também cria um incentivo competitivo: empresas que conseguem operar flywells dentro do compliance têm um moat regulatório. Dados de interação em português brasileiro são escassos e valiosos. Quem os coleta e usa de forma regulada está construindo um ativo que concorrentes internacionais não podem simplesmente importar.
Modelos menores, flywheels mais rápidos. O caso da NVIDIA mostrou que um modelo fine-tuned de 8B pode substituir um de 70B em tarefas específicas com acurácia equivalente. Para operações brasileiras rodando on-premise, onde custo de inferência e latência são críticos, a combinação de SLM + data flywheel é particularmente poderosa: modelos menores treinam mais rápido, ciclos de melhoria são mais curtos, e o custo de GPU para retr treino é uma fração do custo de modelos maiores.
Dados de domínio como moat. A pesquisa do Airbnb (Dai et al., 2025) e o caso da NVIDIA (Shukla et al., 2025) convergem em um insight: modelos base são commoditized. O diferencial competitivo não está no modelo, está nos dados de feedback proprietários gerados por usuários reais fazendo tarefas reais. Em português brasileiro, esse moat é ainda mais forte: datasets de interação em PT-BR são raros, e quem os tem está construindo uma vantagem que não pode ser replicada do exterior.
8. Arquitetura de referência para um flywheel de produção
Baseado na literatura e nos casos documentados, uma arquitetura de referência para operar data flywells em produção:
- Instrumentação: registrar toda interação em produção com workload_id (tipo de tarefa), timestamp, sinais implícitos (cópia, edição, abandono, reformulação) e explícitos (thumbs, correções, adoção)
- Pipeline de curadoria: deduplicar, filtrar por qualidade, estratificar por tipo de tarefa e dificuldade, anonimizar dados pessoais
- Avaliação automatizada: LLM-as-judge com métricas decompostas (factualidade, aderência, completude, tom) para pré-filtrar candidatos antes de validação humana
- Retr treino incremental: LoRA/QLoRA em modelos de domínio, com ciclos semanais para prompt/RAG e mensais para fine-tuning
- Deploy canário: promover modelos candidatos gradualmente (5%, 25%, 50%, 100%) com rollback automatizado se métricas degradam
- Governança: logs de decisão, rastreabilidade de dados de treino, documentação de mudanças entre versões
O custo de entrada não é zero. Mas o custo de não ter flywheel é pago em degradação silenciosa, tickets de suporte crescentes e perda de confiança do usuário.
Referências
- Dai, W. et al. (2025). Agent-in-the-Loop: A Data Flywheel for Continuous Improvement in LLM-based Customer Support. EMNLP Industry Track 2025. arXiv:2510.06674.
- Shukla, A. et al. (2025). Adaptive Data Flywheel: Applying MAPE Control Loops to AI Agent Improvement. arXiv:2510.27051.
- NVIDIA (2026). Build Efficient AI Agents Through Model Distillation With the NVIDIA Data Flywheel Blueprint. NVIDIA Developer Blog.
- Pan, T. (2025). Data Flywheels for LLM Applications: Closing the Loop Between Production and Improvement. tianpan.co/blog/2025-09-28-data-flywheels-llm-applications.
- Zylos Research (2026). AI Agent Data Flywheels: Closing the Loop Between Production Deployments and Model Improvement. zylos.ai/research/2026-04-16-ai-agent-data-flywheels-production-feedback-loops.
- Han, G. et al. (2025). RAG vs. GraphRAG: A Systematic Evaluation and Key Insights. arXiv:2502.11371.
- NVIDIA (2026). NVIDIA NeMo Microservices: Data Flywheel Blueprint. GitHub: NVIDIA-AI-Blueprints/data-flywheel.
- Fractal AI (2025). NVIDIA Data Flywheel: The New Operational Model for Continuous GenAI Improvement. fractal.ai/blog.
Quer construir IA soberana?
Fale com a BaXiJen e descubra como agentes autônomos podem transformar sua operação.
Fale conoscoNewsletter BaXiJen
Conteúdo técnico sobre IA, soberania e produto.
Análises com dados reais, papers acadêmicos e lições de produção. Sem spam, sem buzzword. Um email por semana.